引言
在文章《微信读书冷启动书籍推荐初探:一个借助微信用户画像的方法
》1,我们发现用户的阅读偏好与用户属性(性别、年龄、n 线城市、公众号阅读偏好)相关。基于这个发现,我们利用用户属性,给冷启动的新注册用户做个性化推荐,效果较编辑推荐提升约 50%。

思路
假设具有相似用户属性的用户,有相似的阅读偏好。
我们可以把相同性别、相同年龄段、相同 n 线城市的微信读书用户划分成群体,统计每个群体的用户最喜欢的书;对新注册的用户,它的阅读偏好很可能与他所在群体的用户相似。因此根据这个先验知识,可以把他所在群体最喜欢的书籍推荐给他。
A/B 测试设计
微信读书搭建了书籍推荐 A/B 测试的基础设施,通过如下方法统计不同推荐策略的转化率:
- 在推荐书籍时,后台记录日志:『用户 推荐书籍 推荐策略 推荐位置标识符 时间』
- 在用户把书籍加入书架时,前端上报日志:『用户 推荐书籍 推荐位置标识符 时间』
- 统计时,给定推荐策略、推荐位置标识符、时间范围,可通过 Spark 脚本统计推荐/加书架转化率
本次实验把有属性的用户随机分成两组:
- 个性化推荐组(实验组)
- 编辑推荐组(对照组)
对个性化推荐组的用户,把用户所在群体热门书单推荐给他们。编辑推荐组,沿用以往的固定书单策略。二者在 App 界面的表现形式没有任何差异,只是书籍的不同。
推荐算法实现
- 把用户按属性(性别、年龄、n 线城市)划分成多个群体
- 对每个群体,统计群体用户最喜欢的书籍,按热度排序,做成推荐书单
- 对于每个新注册的用户,根据用户属性找出他所属的群体对应的推荐书单,以新手卡片的形式展示
效果评估
统计新手卡片前十本书推送/加书架转化率,得到表格:
| 日期 | 个性化推荐 | 编辑推荐 |
|---|---|---|
| 20161210 | 1.56% | 0.97% |
| 20161211 | 1.58% | 1.02% |
| 20161212 | 1.56% | 1.10% |
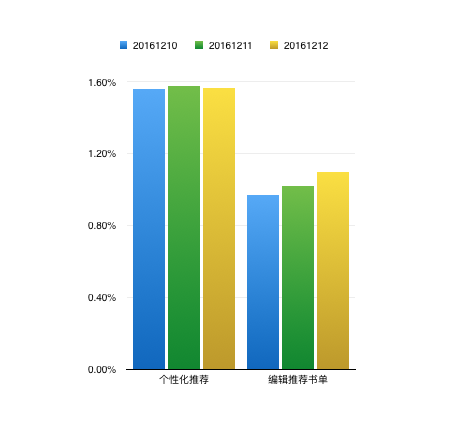
可以看到,个性化推荐的转化率,比编辑推荐提升了约 50%。
未来工作
-
可以探索使用其他用户属性,来划分用户群体,使推荐书籍更精准。
-
本次实验使用的热门的书的定义,是用户感兴趣的书(阅读了 10 分钟且超过了 30% 或者评分大于60分)。未来可以调整热门的定义,如用户评分最高的书,评论最多的书,或者加权综合,来提高转化率。
