MSRA 的 Kaiming He et. al. 在 CVPR15 发表了 ResNet [1],即残差网络,在网络的输入层加入了残差函数,使得更深层神经网络优化更容易。用 152 层 ResNet (比 VGG 深 8 倍)学习 ImageNet 数据集,达到 3.57% 的错误率在 ILSVRC 2015 中名列第一。
在 Deep CNN 中,通常可以增加网络层数,来加强学习能力。
随着网络加深,通常会遇到两个问题:
- 梯度消失 / 梯度爆炸,通常可以用 Batch Norm / 梯度截断方法解决
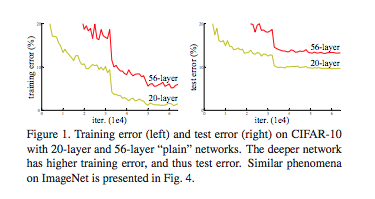
- 退化问题:train accuracy 趋于饱和,这不是过拟合引起的,因为增加层数,train error 会随之增加,如 Figure 1 所示。它意味着不是所有的神经网络都容易优化。
对退化问题,有一个解决方法:构建更深的模型时,added layer 是恒等映射,其他 layers 是从学习好的浅层模型复制过来。这种解决方法表明,更深的模型,相对于浅层的模型,不应该产生更高的训练误差。实验显示,目前 solver 无法很好地求解。
在这篇论文中,提出了 deep residual learning framework 来解决这个退化问题。让每个 layer 拟合残差映射(residual mapping),而不是拟合 underlying mapping,如 Figure 2 所示。
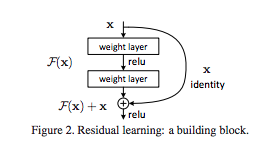
如果 add 操作输入和输出的大小不同,那就可以使用零填充或投射(通过 1×1 卷积)来得到匹配的大小。
记原始映射(original mapping)为 ,残差映射(residual mapping)为 。我们假设残差映射更容易优化。极限情况下,如果恒等映射(identity mapping)是最优的,那么把 residual push to zero 比拟合恒等映射(stack of nonlinear layers) 更容易。
ResNet 作者将这些问题归结成了一个单一的假设:直接映射是难以学习的。而且他们提出了一种修正方法:不再学习从 到 的基本映射关系,而是学习这两者之间的差异,也就是「残差(residual)」。然后,为了计算 ,我们只需要将这个残差加到输入上即可。
其中为 identity 是 shortcut connection,它不增加模型的计算复杂度和参数,同时也容易用现有框架(Keras / Caffe)实现。
论文的实验表明:
- Deep ResNet 容易优化,而 CNN 随着深度增加,train error 增加
- ResNet 比 CNN 更容易通过增加深度(500~1k 层)来提高准确率,参数更少,训练时间更快。
网络结构如 Figure 3 所示:
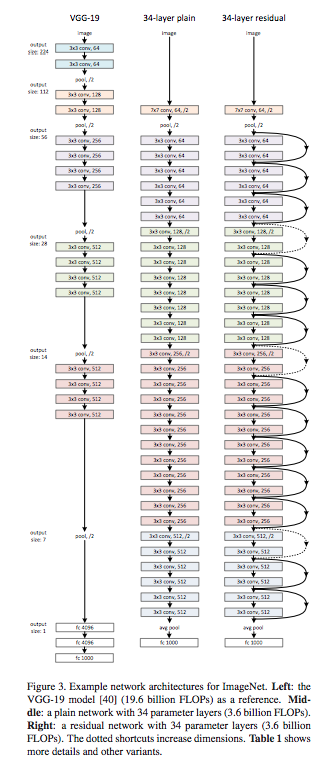
在 keras.applications.resnet50 中 ResNet 结构定义如下。其中 conv_block 和 identity_block 的区别是 identity 增加了卷积计算。
1 | x = Conv2D(64, (7, 7), strides=(2, 2), padding='same', name='conv1')(img_input) |
1x1 卷积
下图是一个更深的残差函数,称为 Bottleneck,使用了 1x1 卷积 对输入输出进行降维,加速计算,减少网络参数:

其中 1x1 卷积的作用,是在保持 feature map 尺度不变的前提下,线性组合不同channel的像素点,增加或减少 depth,完成升维或者降维。
经过激励层,1x1 卷积在前一层学习表示上添加了非线性激励,提升网络表达能力。
