https://zhuanlan.zhihu.com/p/56176647
https://tech.meituan.com/2019/11/14/nlp-bert-practice.html

独热编码语言模型
要点:用 one-hot 向量表示词,用 Bag-of-Words multi-hot 向量表示句子。
问题:维度灾难,语义鸿沟
矩阵分解语言模型
基于SVD
对共现矩阵(Window based Co-occurrence Matrix / Word-Doc Matrix)A 分解
问题:矩阵稀疏,计算复杂度高,高频词影响结果,一词多意问题。
统计语言模型
对于语言序列 ,语言模型用于计算序列出现的概率
N-gram
假设第n个词出现仅与n-1个词有关(马尔可夫假设)。
当 n = 2 有
浅层神经网络语言模型
NNLM
《A Neural Probabilistic Language Model》PDF Bengio 2003 提出,用 NN 代替 N-gram 基于统计预估模型的方法。
用前 n-1 个词去预测第n个词的概率,通过 softmax 输出维度 d 的向量,表示每个词出现的概率。
输入 n-1 个词作 emb lookup 后拼接(x),输入 tanh,加上残差
最后用 softmax 对输出概率作归一化
P(w_t |w_{t−1},···w_{t−n+1}) = \frac{e^{y_{w_t}}}{\sum_i e^{y_i}} .其中 tanh -> softmax 最为耗时,后续算法基于 NNLM 改进。
Wordvec
要点:学习单词的 context 相似性特征;CBOW 目标最大化通过上下文词预测当前词的生成概率,Skip-Gram 目标最大化通过当前词预测上下文词的生成概率。
问题:无法学习句法、语义特征
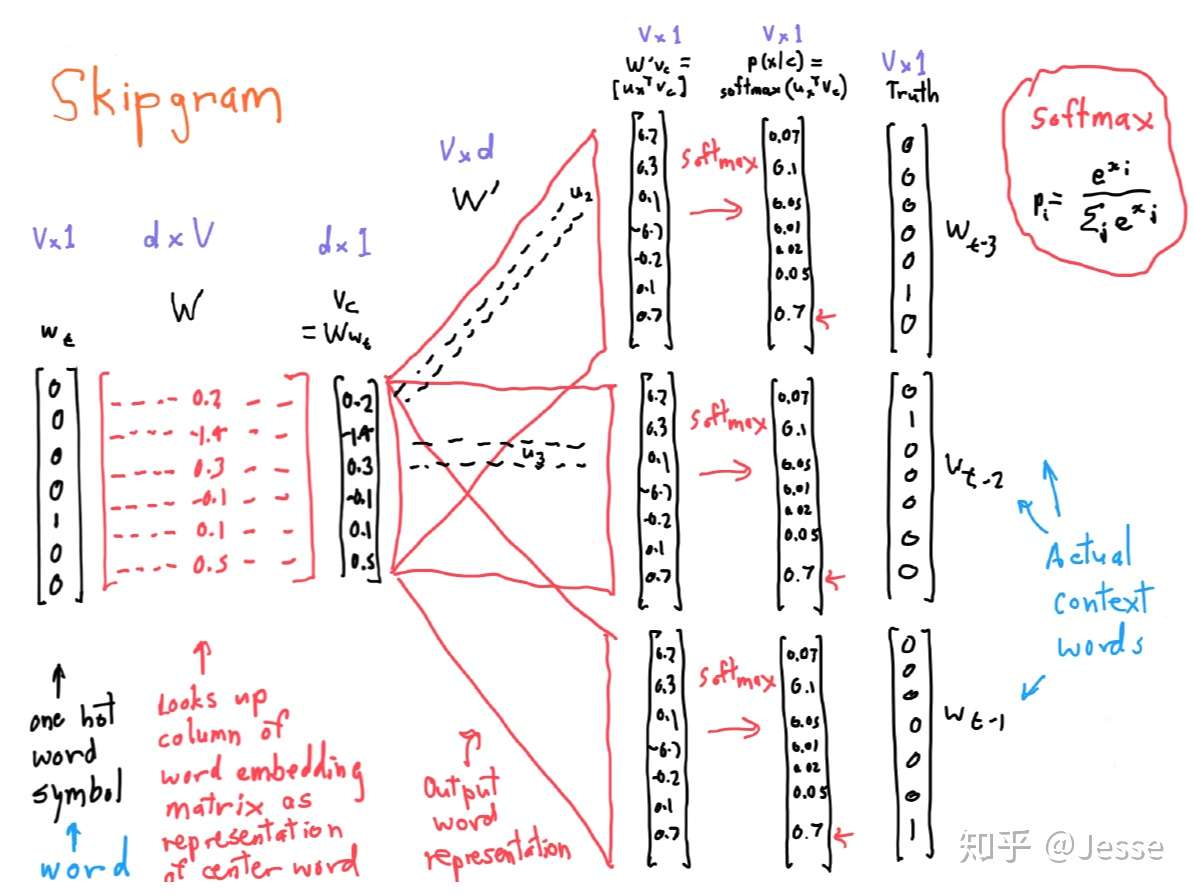
SkipGram
目标函数
其中条件概率为
其中, 表示数据机中样本窗口数,m 表示样本窗口大小,W 表示词表大小。
因为对同一样本窗口,CBOW 模型计算一次梯度, SkipGram 计算窗口大小次数的梯度。SkipGram 对低频词到表示通常优于 CBOW,而速度慢于 CBOW。论文中引入负采样和层次Softmax来提高效率。
https://zhuanlan.zhihu.com/p/54578457
https://mp.weixin.qq.com/s/FwaCMCfLPpQ6YqbSwZeNxA
| 对比 | ELMo | GPT | BERT |
|---|---|---|---|
| 输入层 | 词序列 | 词序列 | 词序列+句子向量+位置向量 |
| 网络结构 | 双向 LSTM | Trans 单向编码器 | Trans 双向编码器 |
| 预训练任务 | 双向语言模型 | 单向语言模型 | 掩码语言模型+下一句预测 |
| 融合方式 | 特征融合 | 参数微调+辅助任务 | 参数微调 |
自回归语言模型
Autogressive LM,通过上文预测下一个字,或者反之。
Seq2Seq
论文:
《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》PDF Bengio Google 2014,RNN ENcoder-Decoder
《Sequence to Sequence Learning with Neural Networks》PDF Quoc V. Le Google 2014,LSTM ENcoder-Decoder
要点:
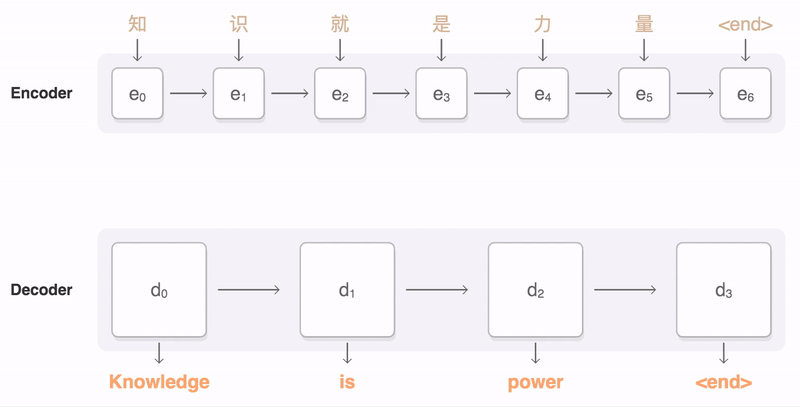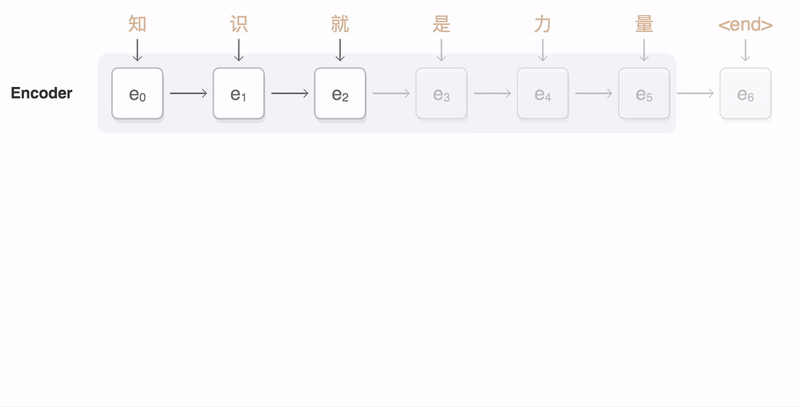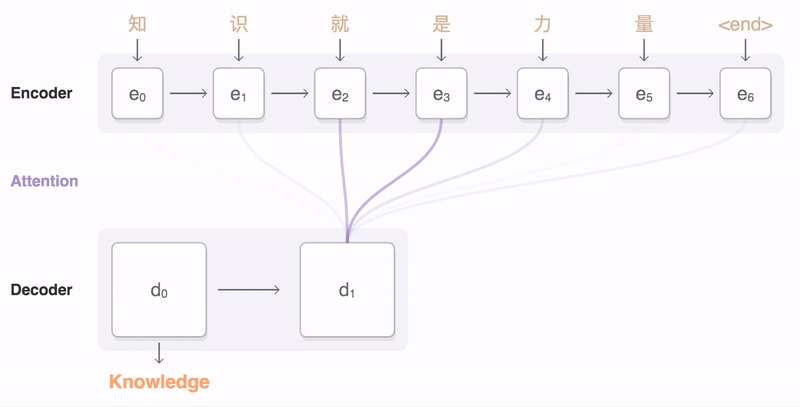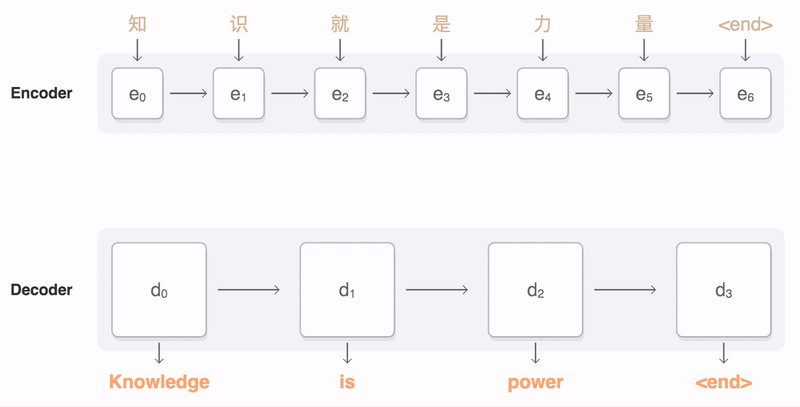
实现:https://google.github.io/seq2seq/ https://github.com/google/seq2seq
ConvS2S
论文:《Convolutional Sequence to Sequence Learning》PDF FAIR 2017
参考:https://zhuanlan.zhihu.com/p/60524073
Transformer
论文:《Attention is All You Need》PDF 2017
要点:与 LSTM GRU 等循环网络相比,通过 Self-Attention 机制能够高效学习长距离 token emb 交互,并行性好,计算复杂度低。BLEU 41 SNLI 89.3
![]()
优点:
Scaled Dot-Product Self-Attention
Multi-head Attention
Point-wise Feed-Forward Networks
Positional Encoding
- 硬编码:sinosoidal function,在偶数位置正弦编码,在奇数位置余弦编码。
- 软编码:learnable embedding lookup
效果相近,前者更容易外推到更长序列。
Optimizer
Adam with
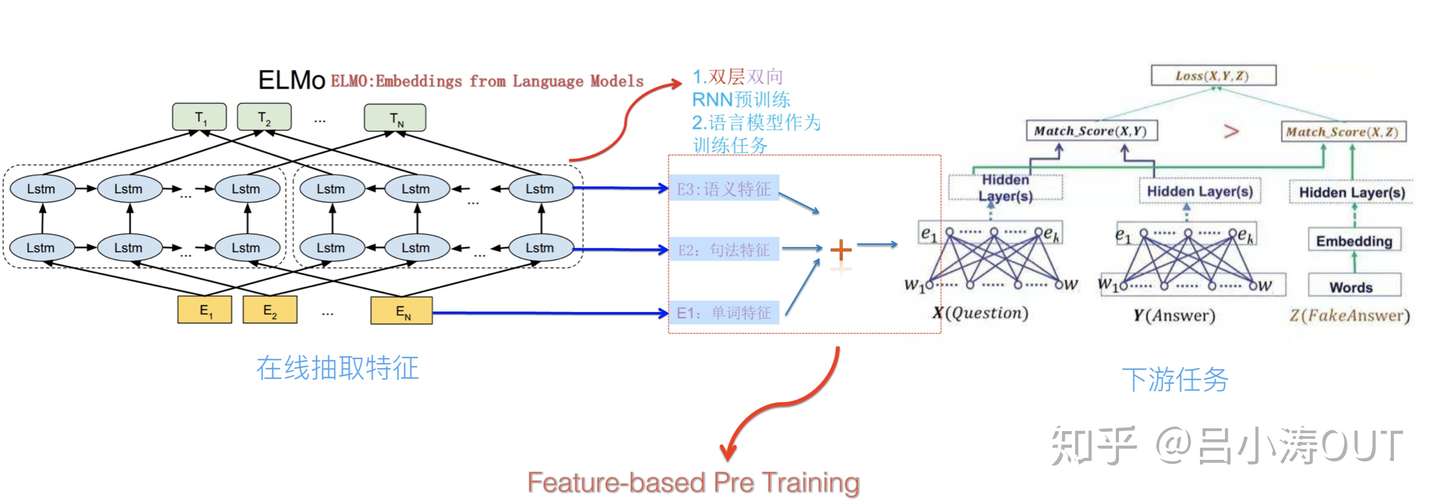
ELMo
Embedding from Language Models
论文:《Deep contextualized word representations》 PDF 2018
要点:两层双向 LSTM 学习句法和语义特征,解决一词多义问题。SQuAD 85.8 SNLI 88.0
比如 I like apple [product],其中 apple 根据上下文调整 emb
与之前工作不同的是,该模型不仅去学习单词特征,还有句法特征与语义特征。后两者的特征是来自LSTM的隐含输出向量。这里的模型目标是预测对应位置的下一个单词(也就是T1的向量应该预测出E2的单词)。
模型训练完,我们就可以得到单词,句法以及语义特征。也就是在一个句子中每一个单词将会对应三个向量,然后三者共同构建成下游任务的输入。比如下游任务就是一个对话系统,整个流程如下图所示。
总结就是ELMo模型是通过语言模型任务得到句子中的单词的向量,这个向量是结合左向右向的信息,但是仅仅是拼接的实现。
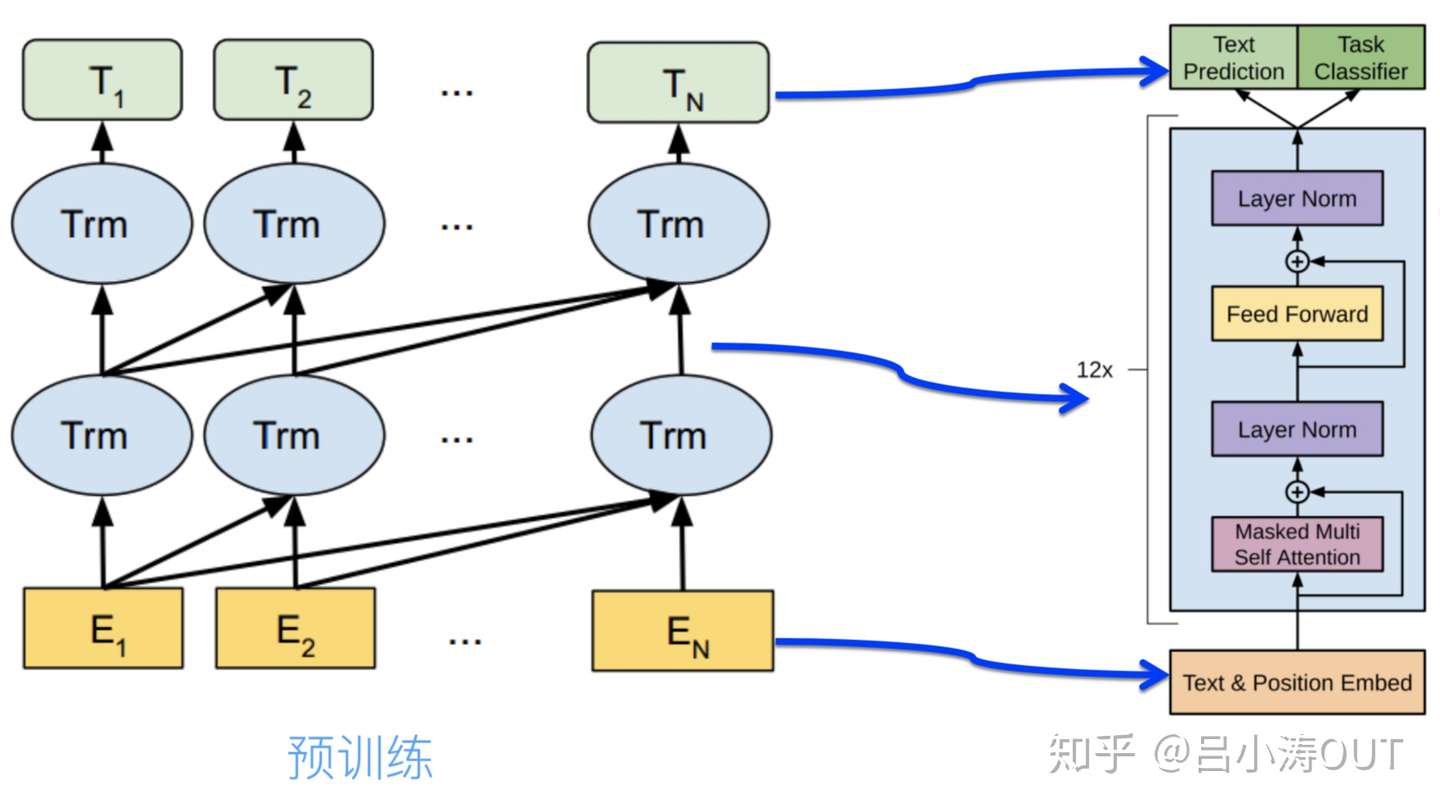
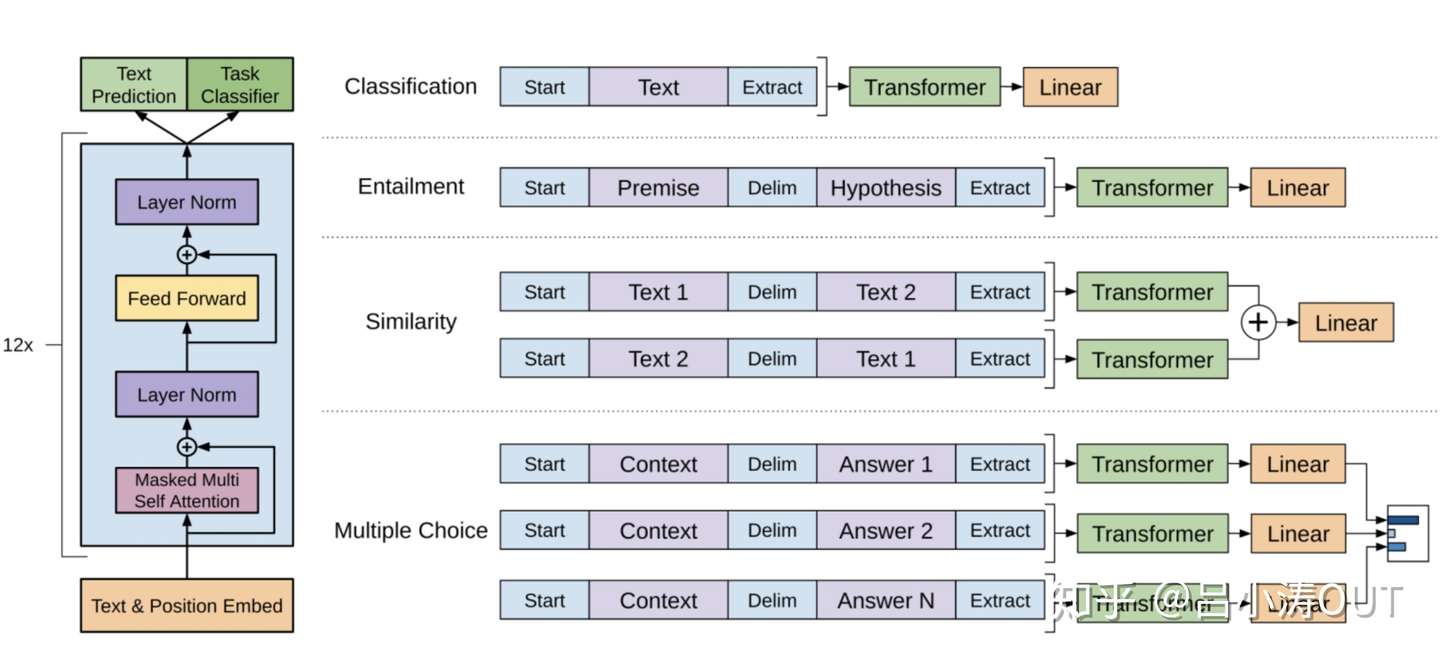
GPT
论文:《Improving Language Understanding by Generative Pre-Training》PDF 2018
要点:引入单向 transformer 替换 LSTM,模型的任务有txt prediction与Task classifier。需要注意的是这里的transformer只有decode部分。
得到预训练的模型,然后在这样的模型后面再次接上下游任务。与ELMo只提供向量不同,这里预训练的模型一同提供给下游的任务。这里模型的向量是可以随着新的下游任务发生微小的调整,也就是fine-tune。
自编码语言模型
Autoencoder LM,区别于自回归 LM,根据上下文预测中间词。
如 BERT 输入随机 mask 一部分词对其预测,类似 Denoising Autoencoder(输入噪音图片,输出去噪图片)。
优点是可以利用上下文进行预测,缺点输入侧引入 Mask 标记,导致预训练阶段和 Fine-tuning 阶段(无 Mask 标记)不一致问题。BERT 这个方法缓解这个问题:对 15% 需要 Mask 词汇,80% 概率用 Mask、10% 用其他词替换、10% 维持不替换。
BERT
论文:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》PDF 2019
要点:Transformer 双向编码器 + 掩码语言模型;先用两个任务预训练模型,再接入任务塔进行 fine-tune。
数据:BooksCorpus、Wiki,大小13G。

意义:
- 真正双向多层语言模型,词语义建模+上下文同时建模
- 显式对句子关系建模
预训练:
- MLM, Masked Language Model:对输入词,构建完形填空任务。改善以往模型自左向右,或浅层拼接自左向右、自右向左模型的上下文学习能力
- NSP, Next Sentence Prediction:判断两句时候相连的二分类问题,用于 QA 任务;最近研究发现,去掉 NSP 影响不大。
网络结构:全连的网络结构(与 GPT 比较)。
输入向量:词向量( / / ),段落向量(segment embedding, / )与位置向量(position embedding, ),都需要模型学习。
输入的格式:增加了 ,为了能同时表达 <单句> 和 <问题句, 答案句="">,给下游各种任务。
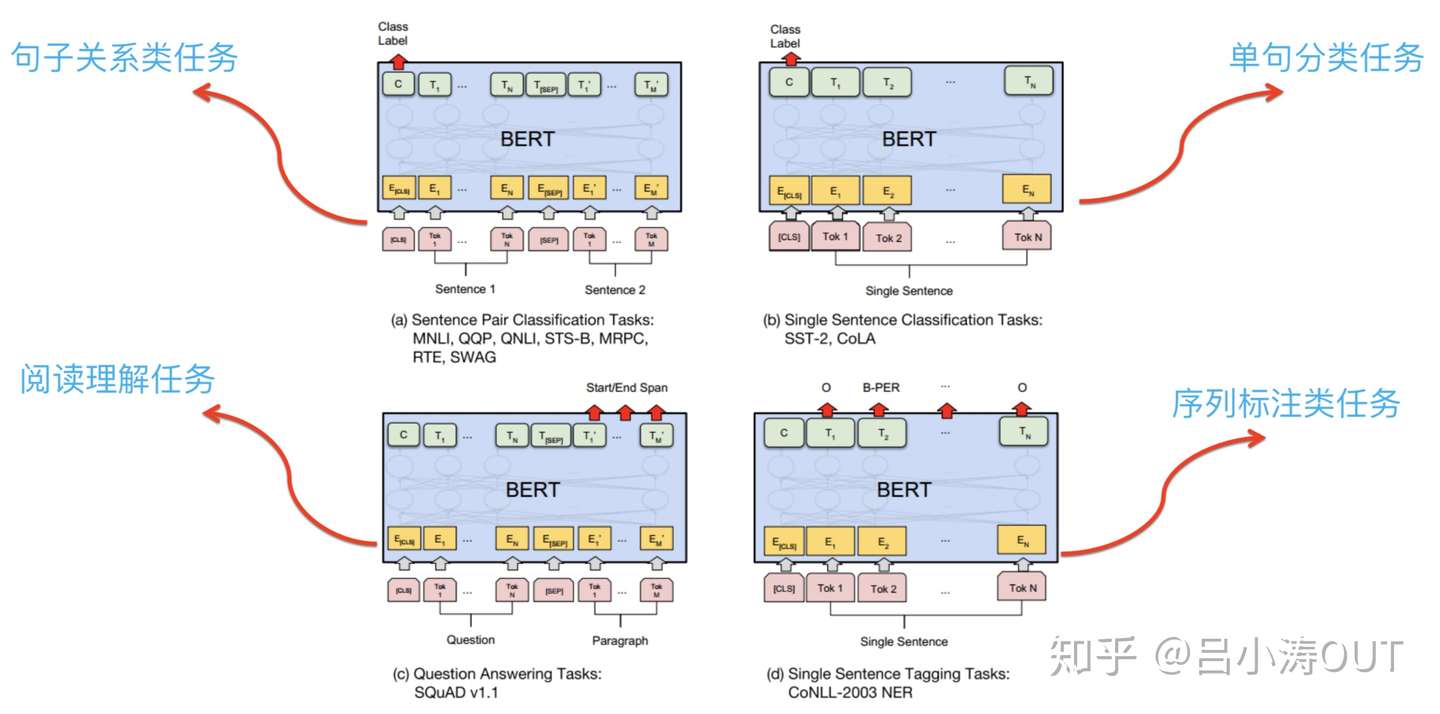
MT-BERT
文章:https://tech.meituan.com/2019/11/14/nlp-bert-practice.html
要点:
- 模型轻量化 & 分布式训练 & 推导加速
- 领域自适应:在 Google 中文BERT模型上加入领域数据
- 知识融入:Knowledge-aware Masking,融入实体知识,避免如 “宫保鸡丁”和“宫保鸡丁酱料” 距离相近的问题
- 单句分类——细粒度情感分析,Share Layers (多路并行的Attention) + Task-specific Layers,对文本在各个属性上的情感倾向进行分类预测(环境、服务、口味多分类)
- 介绍其他任务应用,如推荐理由场景化分类、Query意图分类
RoBERTa
论文:《RoBERTa: A Robustly optimized BERT approach》PDF ACL19
要点:更多的数据,采取更精妙的训练技巧,训练更久一些
效果:在 GLUE / RACE / SQuAD 取得 SOTA
ALBERT
论文:《ALBERT: A Lite BERT for Self-supervised Learning of Language Representations》PDF ICLR20
要点:压缩 BERT,从 100M 到 12M
优化:
- Factorized embedding parameterization
- Cross-layer parameter sharing
- Inter-sentence coherence loss
《美团BERT的探索和实践》URL 模型裁剪
排列语言模型
Permutation LM,基于自回归 LM,通过 Attention Mask 实现双流自注意力,融入双向语言模型。
XLNet
论文:《XLNet: Generalized Autoregressive Pretraining for Language Understanding》PDF Google 2019
参考:《XLNet:运行机制及和Bert的异同比较》URL
数据:BooksCorpus、Wiki、Giga5、CluWeb、CommonCrawl,大小16G、19G、78G。
要点:
-
解决自回归 LM 如 ELMO 的问题:只编码单向语意
-
解决自编码 LM 如 BERT 的问题: (a) 预测 Mask 词之间互相独立的假设 (b) 训练使用 Mask 预测中不用造成的误差
-
提出排列 LM,通过 Attention Mask 随机排列输入句子、预测某个位置的词。
最新进展
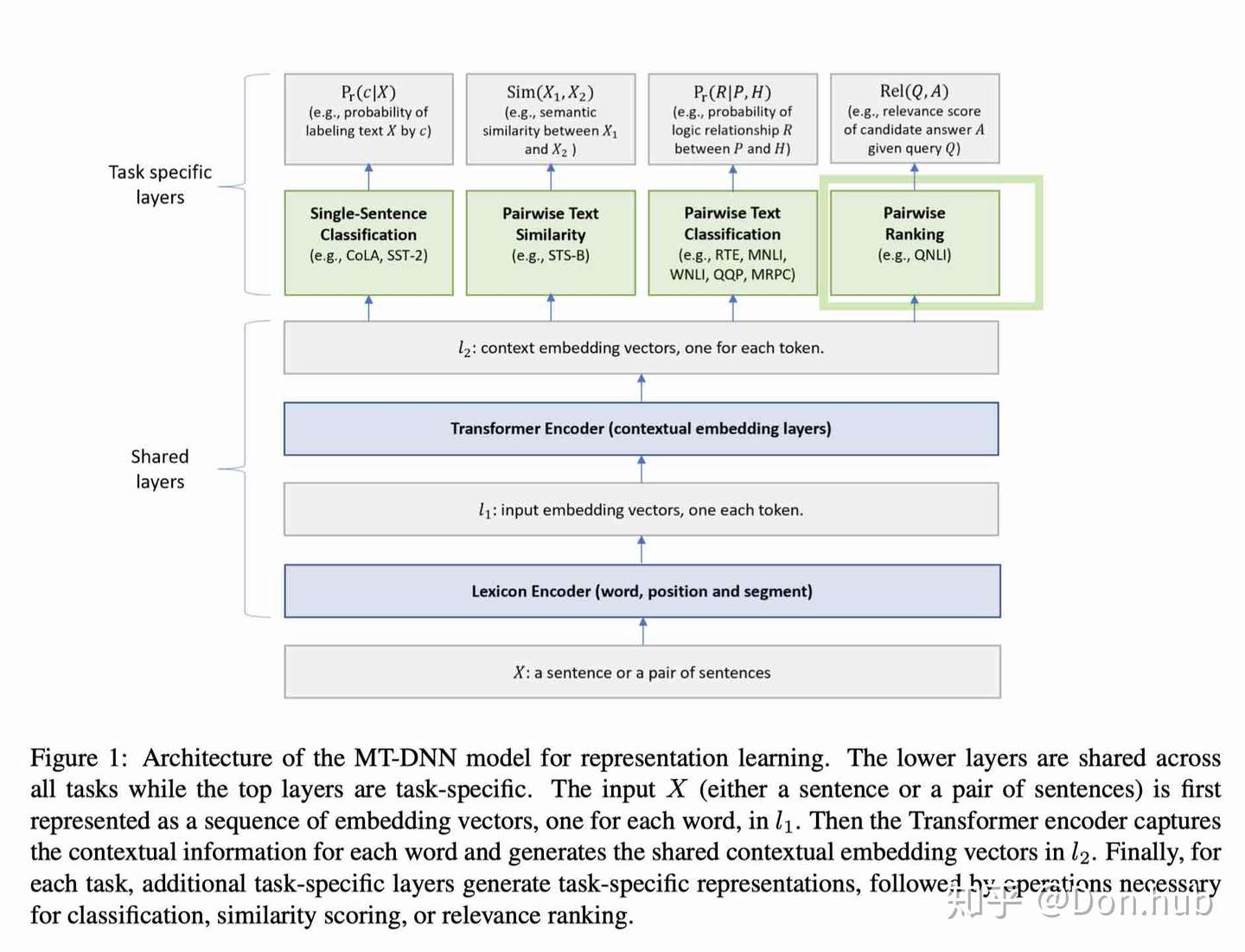
MT-DNN
论文:《Multi-Task Deep Neural Networks for Natural Language Understanding》PDF MSR 2019
T5
论文:《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》PDF Google 2020
介绍:https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
要点:提出 T5 框架,涵盖所有 NLP 任务到单一 text-to-text 模型。

附录
NLP可以分为自然语言理解(NLU)和自然语言生成(NLG)。
NLU 较流行的是 GLUE(General Language Understanding Evaluation) ,集合了九项NLU的任务:
- CoLA(The Corpus of Linguistic Acceptability):纽约大学发布的有关语法的数据集,该任务主要是对一个给定句子,判定其是否语法正确,因此CoLA属于单个句子的文本二分类任务;
- SST(The Stanford Sentiment Treebank),是斯坦福大学发布的一个情感分析数据集,主要针对电影评论来做情感分类,因此SST属于单个句子的文本分类任务(其中SST-2是二分类,SST-5是五分类,SST-5的情感极性区分的更细致);
- MRPC(Microsoft Research Paraphrase Corpus),由微软发布,判断两个给定句子,是否具有相同的语义,属于句子对的文本二分类任务;
- STS-B(Semantic Textual Similarity Benchmark),主要是来自于历年SemEval中的一个任务(同时该数据集也包含在了SentEval),具体来说是用1到5的分数来表征两个句子的语义相似性,本质上是一个回归问题,但依然可以用分类的方法做,因此可以归类为句子对的文本五分类任务;
- QQP(Quora Question Pairs),是由Quora发布的两个句子是否语义一致的数据集,属于句子对的文本二分类任务;
- MNLI(Multi-Genre Natural Language Inference),同样由纽约大学发布,是一个文本蕴含的任务,在给定前提(Premise)下,需要判断假设(Hypothesis)是否成立,其中因为MNLI特点是集合了许多不同领域风格的文本,因此又分为matched和mismatched两个版本的MNLI数据集,前者指训练集和测试集的数据来源一致,而后者指来源不一致。该任务属于句子对的文本三分类问题。
- QNLI(Question Natural Language Inference),其前身是SQuAD 1.0数据集,给定一个问句,需要判断给定文本中是否包含该问句的正确答案。属于句子对的文本二分类任务;
- RTE(Recognizing Textual Entailment),和MNLI类似,也是一个文本蕴含任务,不同的是MNLI是三分类,RTE只需要判断两个句子是否能够推断或对齐,属于句子对的文本二分类任务;
- WNLI(Winograd Natural Language Inference),也是一个文本蕴含任务,不过似乎GLUE上这个数据集还有些问题;
NLG 常见的数据集:
- BLEU(机器翻译)《BLEU: a Method for Automatic Evaluation of Machine Translation》PDF IBM 2002
- ROUGE(自动摘要)、Rouge-N、Rouge-L、Rouge-W、Rouge-S
- METEOR(机器翻译、自动文摘),《METEOR: An automatic metric for mt evaluation with improved correlation with human judgments》PDF CMU 2005
- CIDEr(图像)《CIDEr: Consensus-Based Image Description Evaluation》PDF CVPR 2015
