引言
在文章 学习协同过滤推荐 \w 100行Python代码 中,介绍了基于物品的协同过滤推荐,根据 user-item 评分矩阵,找出与给定 item 评分最接近的物品,作为推荐结果。
在本文中,把书籍名称看作单词,以用户喜欢的书籍看作句子,利用 word2vec 模型构建了一个书籍的向量空间。对给定书籍,找出与其距离最近的书籍,作为推荐结果。
本文用 Python 60 行代码实现了一个 Demo,得到每本书籍在向量空间的表示,输出基于书籍的协同过滤推荐结果。
TODO: https://shomy.top/2017/07/28/word2vec-all/
word2vec
简介
word2vec,是 Google 的 Mikolov 等人在 NIPS2013 发表的论文 Efficient Estimation of Word Representations in Vector Space / Distributed Representations of Words and Phrases and their Compositionality 提出的模型,包括 Skip-gram(一对多)和 CBOW (多对一) ,如下图所示。
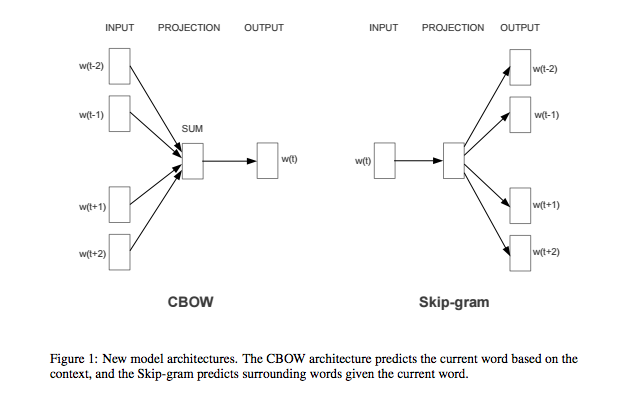
word2vec 在没有词性标注的情况下,能够从原始语料学习到单词的向量表示,比较单词间的语义、句法的相似性。word2vec 速度快,得到 embedding vector 具有 analogy 性质,例如:
vector("King") - vector("Man") + vector("Woman") ≈ vector("Queen")利用模型的特点,我们可以把书籍看作单词,把每个用户喜欢的书籍序列看作句子,用这些数据训练 word2vec 模型,得到每本书籍的向量表示。在推荐时,根据用户在读书籍 ,在向量空间中找到与其距离相近的书籍作为推荐。
与 Item-CF 相比,word2vec 在推荐时更加灵活,书籍向量可以相加、相减,能够更灵活地满足个性化推荐需求。例如,根据用户 amy 最近喜欢的《浪潮之巅》,考虑到他以前喜欢《从0到1》,不喜欢《寻路中国》,可以这样计算推荐书籍:
vector("浪潮之巅") + vector("从0到1") - vector("寻路中国") ≈ vector("推荐书籍")CBOW
优化 likelihood 目标
其中 表示所有词对 , 是中心词, 是非中心词。
模型定义
优化 log-likelihood 目标
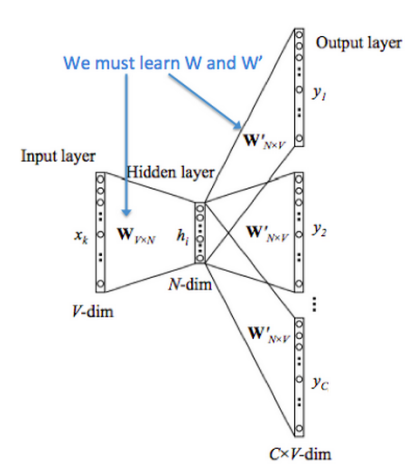
训练中,每个词指派两个向量:中心词向量 和上下文词向量 ,解决 大、同时学习参数 和 W‘ 同步更新的问题。实践中,W 和 W’ 可以共享权值,词嵌入结果可以用 W 或者 W’ 或者拼接。
输入层
假设窗口=5,对输入单词查询词向量、求和
结果输入全连接隐藏层,再到输出层
输出层
在 CBOW 模型中,输出层可以是普通 softmax。改进后的输出层是 hierarchical softmax,以霍夫曼树的叶子节点表示输出单词。用霍夫曼树使得叶子节点的输出概率,累加和等于一。
对第 个非叶子节点,有待训练的参数 ,输入标量 选择左、右分支的概率
叶子节点输出标量
对每个进入输出层的标量 ,按以上方法递归地求得输出
Skip-gram
输入为一个单词向量,经过 continuous projection layer,输入到 log-linear classifier,得到前 n、后 n 个单词。
用同样方法,得到损失函数、损失函梯度函数、更新函数后,用 随机梯度上升算法得到估计参数 、单词向量 。
Hierarchical Softmax
优化 softmax 分母对全部 个单词计算速度,树形 Softmax 使得前向计算复杂度 。
Negative Sampling
Skip-Gram 负采样,SGNS,降低高频词的采样频率。
核心思想是:计算目标单词和窗口中的单词的真实单词对“得分”,再加一些“噪声”,即词表中的随机单词和目标单词的“得分”。真实单词对“得分”和“噪声”作为代价函数。每次优化参数,只关注代价函数中涉及的词向量。采用上述公式解决了两个问题:
- 我们仅对K个参数进行采样
- 放弃 softmax 多分类函数,采用 sigmoid 二分类函数,这样就不存在先求一遍窗口中所有单词的‘“得分”的情况了。
优化目标
\begin{align} L &= \arg\max_\theta \prod_{(w,c)\in D} P(D=1|c,w;\theta) \prod_{(w,c)\in D'} P(D=0|c,w;\theta) \\ &= \arg\max_\theta \prod_{(w,c)\in D} P(D=1|c,w;\theta) \prod_{(w,c)\in D'} \bigg[1 - P(D=1|c,w;\theta)\bigg] \\ &=\arg\max_\theta \sum_{(w,c)\in D} \log \frac{1}{1 + e^{-v_c \cdot v_w}} + \sum_{(w,c)\in D'} \log \frac{1}{1+e^{v_c \cdot v_w}} \end{align}其中 是负样本;P 定义为 sigmoid 二元分类器,较 softmax 简化了输入词的数量:
TF 文档解释
Skip-gram 模型定义:根据历史词 预测出下一个词(或中心词) 的概率
其中 score 计算词与上下文的协调性(通常使用点积)。
目标是最大化似然函估计(MLE, maximum log-likelihood estimation)
优化方法有 Negative Sampling(Q 为二分类 sigmoid)
数据准备
准备 user_prefs.txt:
1 | david 百年孤独 |
训练模型
安装 gensim 包
1 | brew install pip3 |
训练模型
1 | #!/usr/sbin/python3 |
输出结果
书籍的向量表示保存在 word2vec.model 文件:
1 | 14 100 |
推荐结果:
1 | 基于书籍的 word2vec 协同过滤推荐 |
附录
完整源码 Github
TF Word2vec 文档 http://doc.codingdict.com/tensorflow/tfdoc/tutorials/word2vec.html
TF Word2vec r0.7 https://github.com/tensorflow/tensorflow/blob/r0.7/tensorflow/examples/tutorials/word2vec/word2vec_basic.py
chao-ji 实现的 tf-word2vec 完整版 https://github.com/chao-ji/tf-word2vec
Word2vec from scrach https://medium.com/@pocheng0118/word2vec-from-scratch-skip-gram-cbow-98fd17385945
自己动手做聊天机器人 二十五-google的文本挖掘深度学习工具word2vec的实现原理 URL
word2vec 原理 一 CBOW Skip-Gram URL
word2vec 原理 二 Hierachical Softmax URL
word2vec 原理 三 Negative Sampling URL
搜狐新闻参考 AirBNB SGNS URL
