Multi-shot 方法
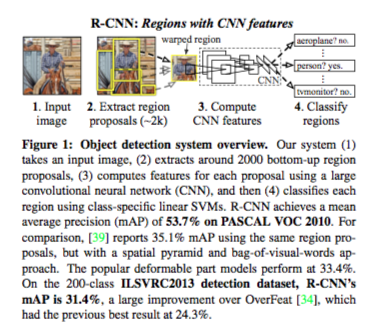
R-CNN
Ross Girshick et. al. 在 2014 [2] 提出 R-CNN,用于 object detection 和 sementic segmentation,比 VOC 2012 的最好模型 mAP (mean average precision) 提升了 30%;在 ILSVRC2013 mAP 达到 31.4%。
R-CNN 使用 Region Proposal 提取出 2000 个 ROI (感兴趣区域),对每个 ROI 使用 CNN + SVM 进行分类如猫、狗、背景。
在 ILSVRC 2012,CNN AlexNet 在图像分类取得了很好的成绩。为填补 CNN 在 object detection 的鸿沟,本文主要解决两个问题:
-
如何用深度网络进行 object detection
以往方法有 1. CNN Softmax + Regressor [4],缺点精度不高 2. 粗暴的 sliding-window detctor,如 ILSVRC2013 冠军 Overfit [3],缺点计算代价高。本文通过 category-independent region proposal 方法,在测试时,该方法生成 2k 张候选截图做为输入,用 category-specific SVM 分类。目前有多种 region proposal 方法,本文用 selective search [4]。分类后,用一些后处理方法来 refined box 以提升精度。
-
如何用小容量样本,训练高容量 CNN
以往方法用 unsupervised pre-train + supervised fine-tuning 训练。本文用大数据集 supervised pre-train (ILSVRC) + 小数据集 supervised fine-tuning (PASCAL),对结果有显著提升。使用 AlexNet 的 pre-train model,把最后一层 4048 x 1000 改成 4048 x 21 (PASCAL 的类别数目)。在 CNN 的输出层,用 category-specific SVM 模型完成分类任务;category-independent linear regression 完成定位,输出 box 坐标。
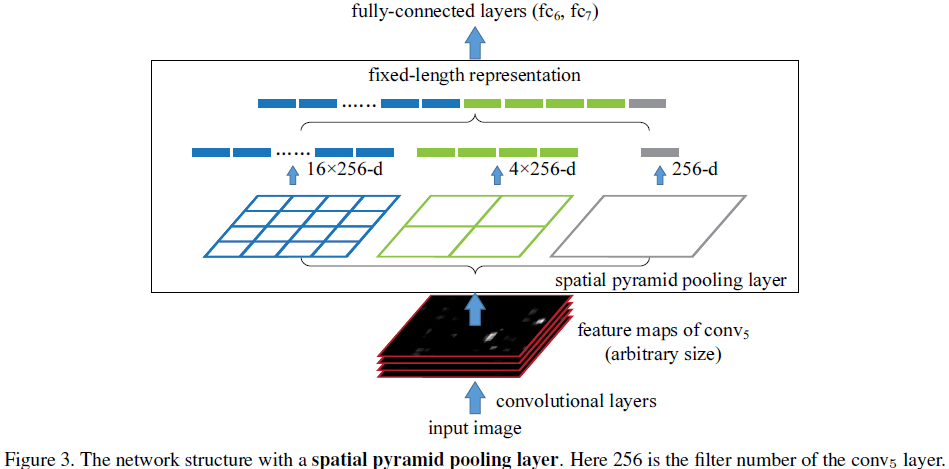
SPPNet
引入 Spatial Pyramid Pooling,SPP结构从细密和粗糙级别上分割图像,然后融合局部的特征。SPP有3个优势:
-
任意size和scale输入,产生固定的输出特征表示,提取整个图片在不同尺度的特征
-
使用多级spatial pooling layer(多个尺寸的pooling),多级pooling对于物体形变具有鲁棒性
-
允许我们在各种size和scale下训练网络,可以增加样本个数(类似数据增益),防止过拟合
Fast R-CNN
R-CNN 存在缺点:
- 测试运行速度慢(50 sec),由 2k region proposal 导致
- SVM 训练时无法更新 CNN 参数
- 复杂的 CNN fintune + SVM + Regressor 三阶段训练流程
为解决 R-CNN 这些问题,Girschick 在 ICCV 2015 [5] 提出 Faster R-CNN,改进有:
- Region of Interest Pooling 机制,让 region proposal 在 conv 后执行,在高阶 feature map 做区域回归和分类,利用共享CNN计算提升测试速度
- SVM 改成 softmax,训练时更新 CNN 参数
- 用 multi-task loss 简化训练流程,end-to-end
在 PASCAL 训练时间从 84 小时降低到 9.5 小时,测试时速度提升 146x,mAP 稍微有提升。
实际每张图片处理时间从 50 sec 到 2 sec。
其中 ROI pooling layer 结构如下图:

ROI pooling layer 是一个max pooling layer。假设有两个超参数 、 把输入的 patch 划分成 个小方格,假设投影的每个 ROI 的 patch 为 ,则每个小方格尺寸是 。而在每个方格中,执行 max pooling layer 操作,两层 FC 后得到 ROI 特征向量,最后分别经过一层 FC 进入 bbox regressor 和分类 softmax 。
损失函数:
其中 是分类 log 损失; 是 bbox 损失。 是类别, 是真实 bbox 坐标, 是预测 bbox 坐标。 表示只计正样本的 bbox 损失。
Faster R-CNN
何凯明在 NIPS 2016 发表 Faster R-CNN [6],通过降低计算瓶颈 Region Proposal 部分,提出 Region Proposal Network 提升速度,是的检测速度达到实时 0.2 sec / 张图像。
RPN 输入图片,输出一系列 bbox 和对应的 objectness score。为了复用 CNN 的计算,我们假设 RPN 和 CNN 共享卷基层。在 conv feature map 上用 的滑动窗口提取特征(256-d)加 ReLU,随后通过两个 FC 层—— cls layer 和 reg layer 输出物体分数和物体区域。在每个滑动窗口区域,都有一个anchor,对应 k 个 region proprosal(4k reg 坐标和 2k cls)。
最后,用 RPN 得到的区域,用 ROI pooling layer + softmax classifier 完成物体检测任务。
在一个网络中的四个 loss:
- RPN classification (good / bad)
- RPN regression (anchor -> proposal)
- Fast R-CNN classification (over class)
- Fast R-CNN regression (proposal -> box)
One-shot 方法
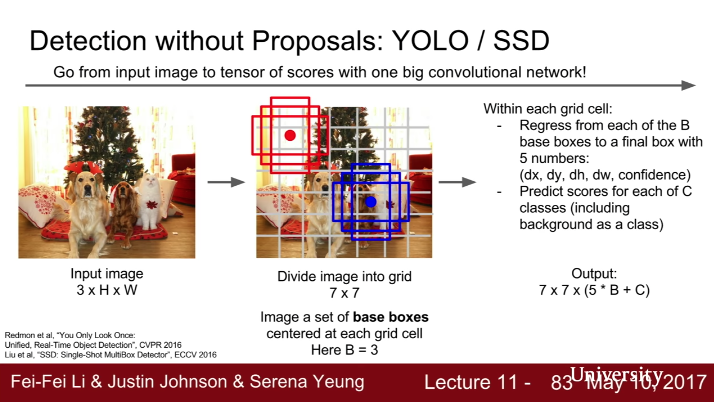
YOLO
速度可以达到 115 FPS,但是准确率不如 R-CNN。
YOLO 把 bounding box 回归和图像分类放入同一个网络。首先把图片划分成 7x7 个 grid,每个 grid 有 B 个 base box,每个 base box 输出 confidence dx dy dw dh 和 C 个类的分数,即网络输出 7 x 7 x (5 * B + C)。
优点:
- 简单,单一网络
- 快
- 整张图像做为输入,能对全局信息进行建模,避免 R-CNN 对背景错误分类的问题
- 能学习到图像的泛化表示,比如在训练时用自然图像,在测试时用艺术图像也能工作
缺点:
- 未达到 state-of-art 方法的进度
- 精度不高,无法处理大分辨率图像的小物体
模型结构:
- 输入图像划分为 7x7 的 grid
- 每个 grid 输出 B 个 bounding box 的 (dx, dy, dw, dh, confidence) ,和分类结果 C,其中 confidence 表示
损失函数定义:
其中用 sum-square error 因为容易优化,尽管和我们最大化 mAP 的目标不完全一致。另外,大部分 box 不包含任何类别,训练时使得包含 object 的 box confidence 趋于 0。为解决这个问题,引入 , ,减少不包含 object 的 loss,增加包含 object 的 loss。
YOLOv2
RetinaNet
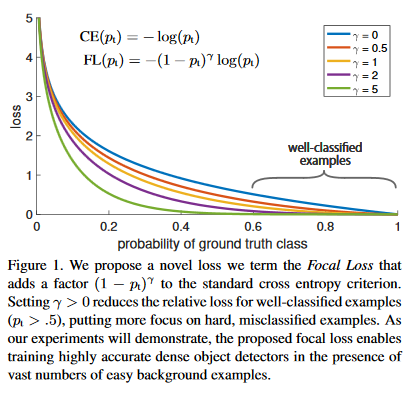
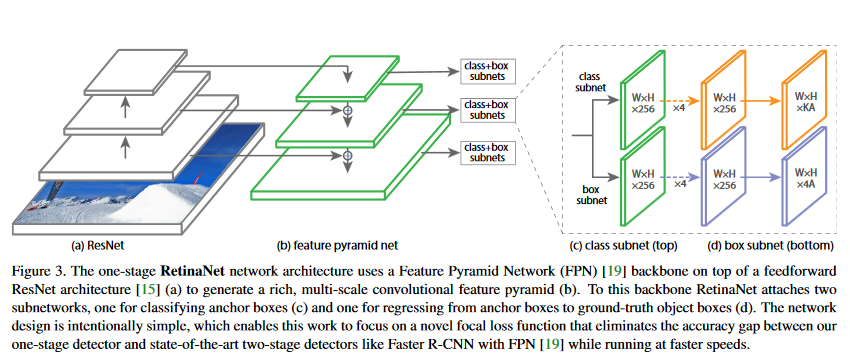
FAIR 在 2017 提出 focal loss,改进 SSD 结构前背景样本悬殊的问题,提升识别准确率。其中 减少成功分类样本的损失(),把更多注意力放在难的、错误分类问题上。
FL 取不同参数的训练收敛结果:
论文实验的网络结构如下,另外 loss 也可用于 R-CNN 结构。
其他技巧
Data augmentation,clip + flip 混合使用。
在 supervised pre-trained model 基础上 supervised fine-turning,可以在训练集样本稀少的情况下,有显著提升 [2]。
Instance Segmentation
Mask R-CNN
He et. al. 2017 提出 Mask R-CNN [8],在 Fast R-CNN 基础上,做 instance segmantation,精确到像素,同时可以做 pose detection。
引用
[1] Lecture 11 Detection and Segmentation, Stanford University School of Engineering Video
[2] Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014. PDF
[3] Sermanet, Pierre, et al. “Overfeat: Integrated recognition, localization and detection using convolutional networks.” arXiv preprint arXiv:1312.6229 (2013). PDF
[4] CS231n Lecture 8 - Localization and Detection Video
[5] Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE international conference on computer vision. 2015. PDF
[6] Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in neural information processing systems. 2015. PDF
[7] YOLO Homepage YOLO900 PDF YOLO PDF
[8] He, Kaiming, et al. “Mask r-cnn.” arXiv preprint arXiv:1703.06870 (2017). PDF
[9] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[J]. IEEE transactions on pattern analysis and machine intelligence, 2018. PDF
[10] SSD: Single Shot MultiBox Detector PDF
[11] 读 Focal Loss URL
