常见的 CTR 预估模型有:
- LR / 决策树系列
- Embedding + 低阶交叉 + MLP:FM / DeepFM / NFM / FNN 系列
- Embedding + 高阶交叉 + MLP:W&D / DCN / xDeepFM 系列
- Attention:RNN CTR / DIN / DIIN / DIEN / CrossMedia / AutoInt(Multi-head Self-attention)
- 多任务联合建模: ESMM / ESM^2 / DUPN
- 双塔模型 DSSM 系列
深度 CTR 预估模型有:
-
Wide&Deep 16 兼具泛化性和记忆性的联合优化,cross product 进行特征交叉
-
DCN 17 使用 CrossNet 拟合任意高阶元素级交互(bit-wise 、上 1 层)
-
DeepFM 17 使用 FM 拟合 emb 向量的二阶交互
-
NFM 17 在 FM 层后增加了 Bi-Interaction Layer 完成池化和特征交叉、 增加 Dense 层
-
AFM 17 在 NFM 结构增加 attention 机制学习交互特征的权重
-
xDeepFM 18 使用 CIN 进行向量级别、高阶元素的交叉(vector-wise、上 n 层)
-
-
FNN 07 用 FM 预训练 emb 向量 + Dense 结构
-
CCPM
-
PNN SNN
-
FGCNN
FiBiNet 19 结合特征重要性和双线性特征交互
-
-
YouTubeDNN 16 通过 pooling 引入用户历史行为序列
-
AutoInt 19 引入 Transformer 中的 multi-head attention 机制
-
BST 19 引入用户行为序列 + Transformer
XGB
优化瓶颈
- 树型结构导致无法增量训练(FTRL)
- 稀疏的类别特征无法有效学习,onehot 后增加计算开销,且每个分类上数据量小(LR 记忆性)
- 特征交叉能力有限
GBDT + LR
Facebook ADKDD 2014
GBDT 叶子结点作为 LR 输入,通过 GBDT 做特征组合引入非线性。
FM
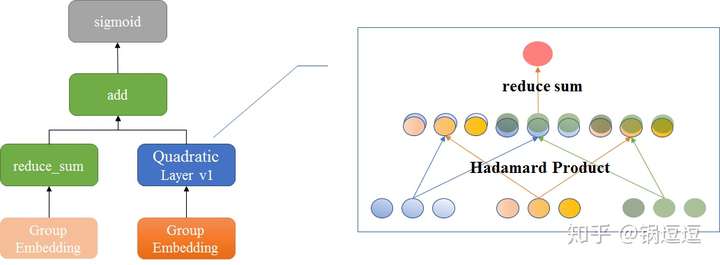
DeepFM
Huawei 2016
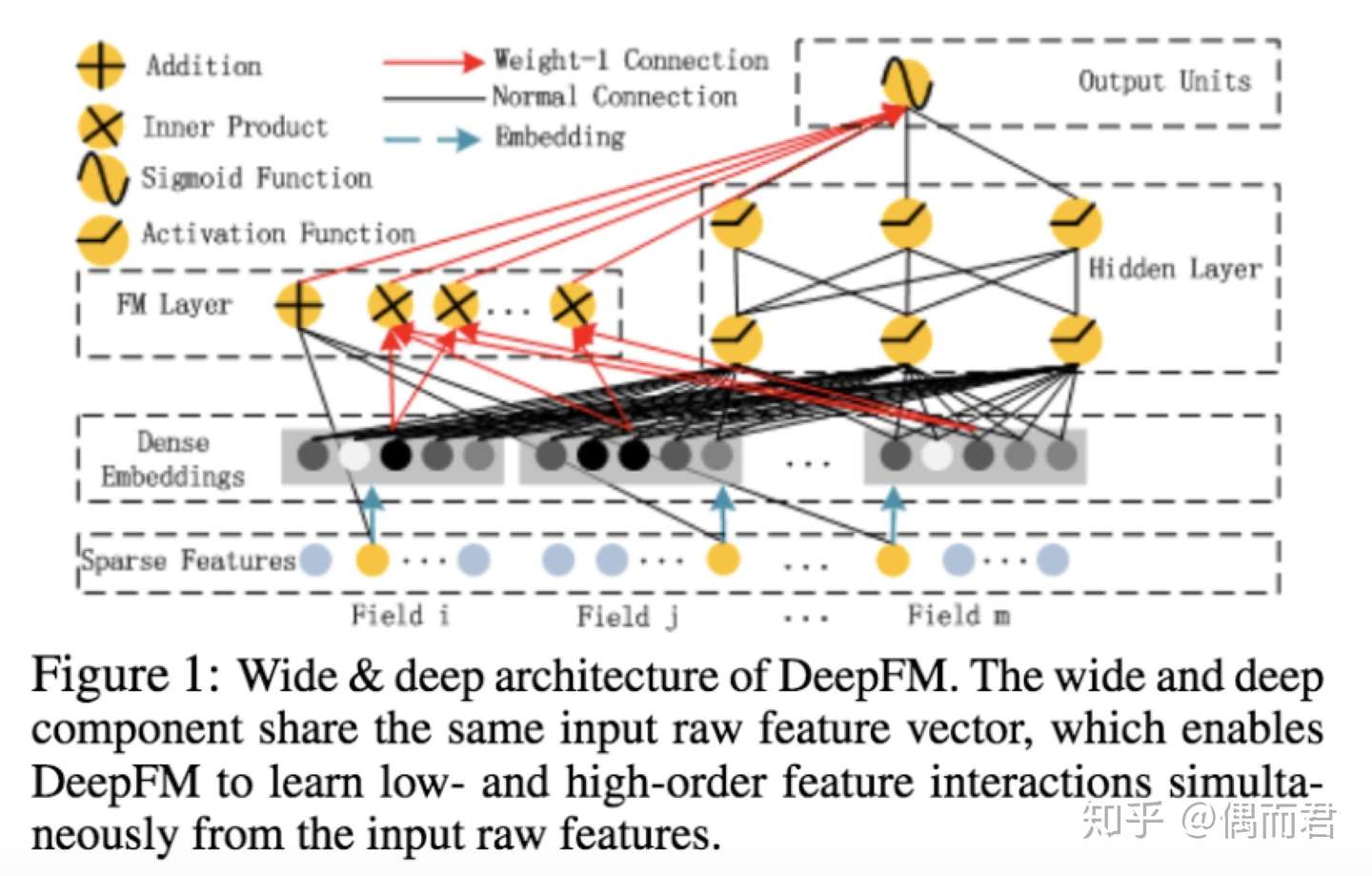
为了同时利用low-order和high-order特征,DeepFM包含FM和DNN两部分,两部分共享输入特征。对于特征i,标量wi是其1阶特征的权重,该特征和其他特征的交互影响用隐向量Vi来表示。Vi输入到FM模型获得特征的2阶表示,输入到DNN模型得到high-order高阶特征。模型联合训练,结果可表示为:
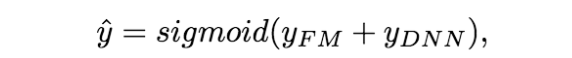
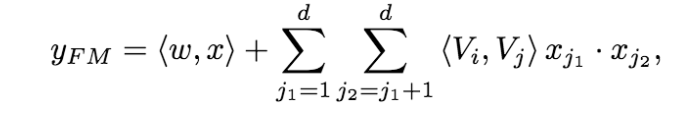
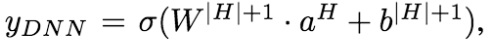
Wide&Deep
Google DLRS 2016
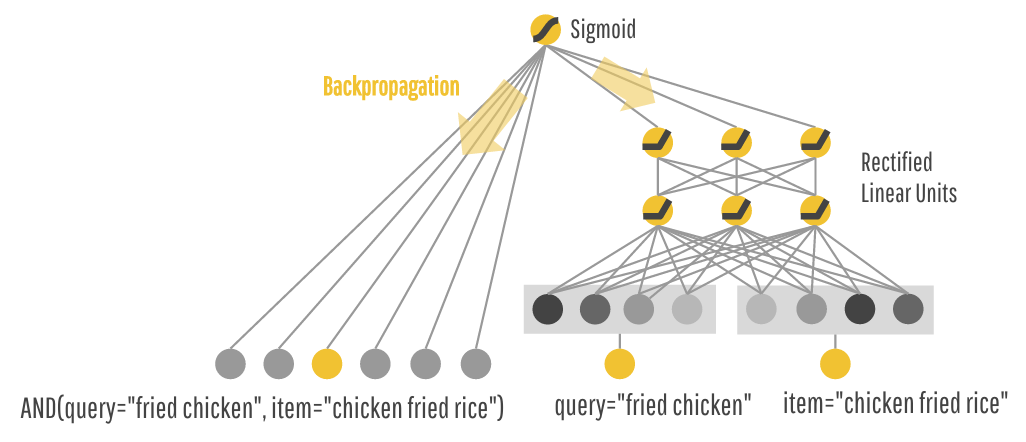
Wide:向量点积特征,具有记忆性。缺点:需要特征工程,不能覆盖未见的 query-item 特征,泛化差。
Deep:引入低维的 embedding,对未见的 query - item 具有泛化性。注意当 query - item 矩阵是稀疏且高秩时(如每个用户的兴趣很窄且小众),较难学习 embedding,出现过度泛化现象。此时需要 Wide 的记忆性来缓解。
训练:joint training 而不是 ensemble。相对而言,joint training 对子模型需要更少的模型容量 / 参数。Deep 泛化部分的不足,仅仅需要少量的 Wide 来弥补。Wide 用 FTRL,Deep 用 AdaGrad。其中 wide 部分类似 ResNet 的 residual shortcut。
工程:共使用 500 Bi 样本。对新样本,增量训练。上线前两个模型预测结果对比,做健全性检验(sanity-check)。
推理公式:
其中 是 sigmoid 函数, 表示特征拼接。
向量点积:
其中 是某个特征, 如果为 1 表示 是 变换的一部分。
向量点击可以进行特征组合,引入非线性,如 AND(gender=female, language=en) 这个特征,当且仅当这个用户的性别为 female,语言为 en 的时候,这个特征值才为 1,其他情况都为 0。
DCN 17’
http://xudongyang.coding.me/dcn/
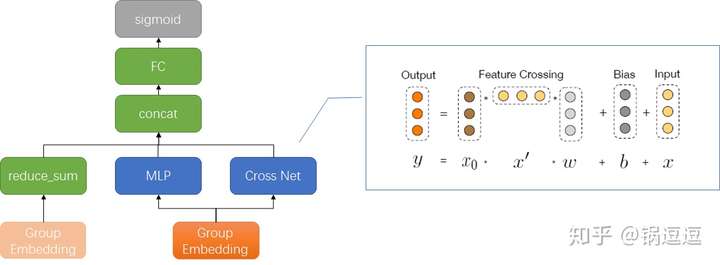
ADKDD 17’ PDF,类似于Wide & Deep Network(WDL),是用复杂网络预估CTR的一种方法。
与 DeepFM 相比,可以自动高阶特征:
- 通过设置交叉网络深度,能够限定交叉阶数
- 每层交叉时,做第零层与第一层的交叉 & 学习残差

其中每个 cross layer,通过学习函数 f 拟合层间残差
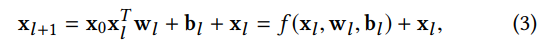

论文在 movielen 数据集上,与 LR FM DNN DeepCrossing 做对比。没有与 W&D 做对比的原因是 W&D 需要领域知识进行特征工程。没有与 DeepFM 对比,是同时期工作。
FNN & SNN & PNN
Feedforward Neural Network, ANN 2007
FM 预训练 emb 向量 + DNN 结构,无 embedding
Self-Normalizing Neural Network, NIPS 2017
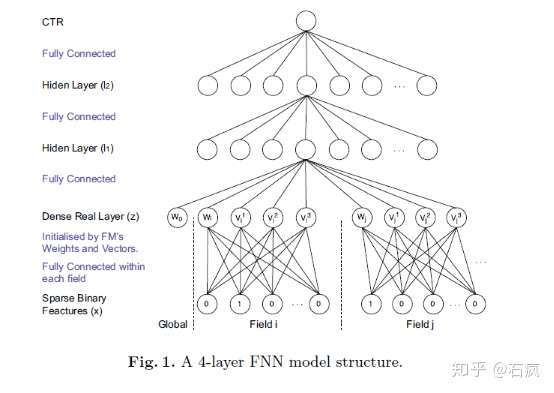
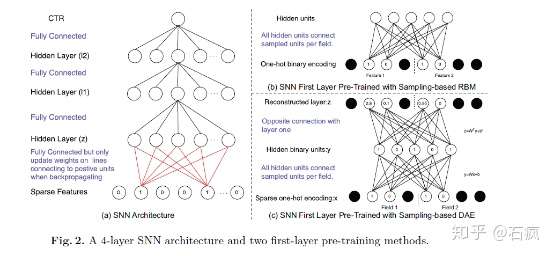
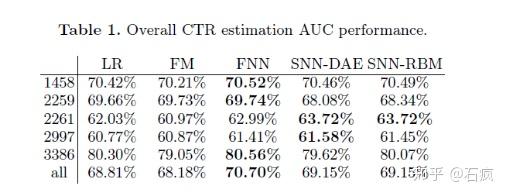
Product-based Neural Networks, ICDM 2016
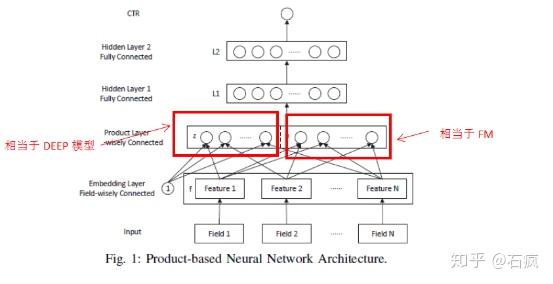
PNN 的 Embedding 和 Hiden Layer 1之间进行一次 inner / outer production,效果不错但增加了全连接规模导致训练较慢。
NFM 17’
Neral Factorization Machine, arxiv 2017 PDF
基于 FM 改进,在 FM 层后增加了 Dense 层 NFM与AFM用于CTR预估
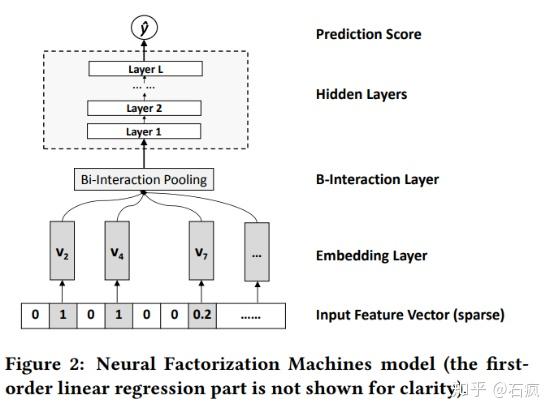
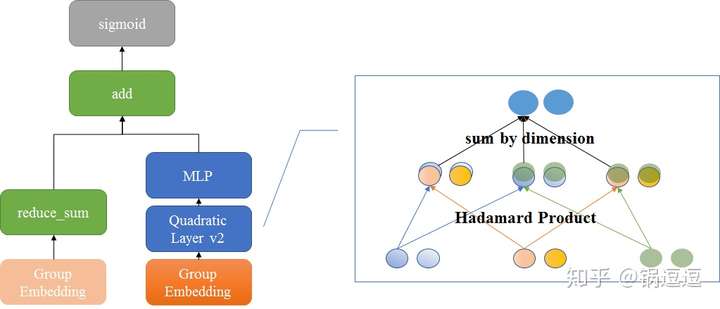
与 YoutubeDNN 的 AVG Pooling 不同,NFM 通过 Bi-Interaction Pooling 完成池化和特征交叉:
其中 是第 i 维特征, 是对应 embedding 矩阵, 是 element-wise product (outer product)。
实现代码:
https://github.com/nzc/dnn_ctr/blob/master/model/NFM.py
https://github.com/lambdaji/tf_repos/blob/master/deep_ctr/Model_pipeline/NFM.py
1 | with tf.variable_scope("BiInter-part"): |
论文在 MovieLen 数据集合与 WDL DCN 模型做对比。
NFFM 18’
NFM 的变种,在 Bi-Interaction 中将 FM 替换为 FFM
实现 https://github.com/guoday/ctrNet-tool/blob/master/models/nffm.py
腾讯 2018 Lookalike 第七名实现 https://github.com/guoday/Tencent2018_Lookalike_Rank7th
腾讯 2019 广告比赛预赛第一名实现 https://github.com/guoday/Tencent2019_Preliminary_Rank1st
AFM 17’
Attentional FM, arxiv 2017 PDF, 浙江大学 Jun Xiao et. al.
https://zhuanlan.zhihu.com/p/38517948
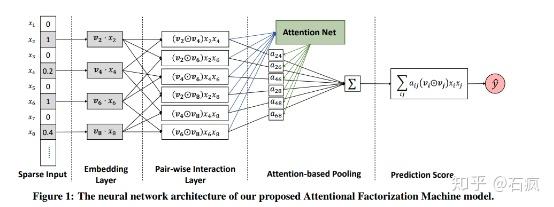
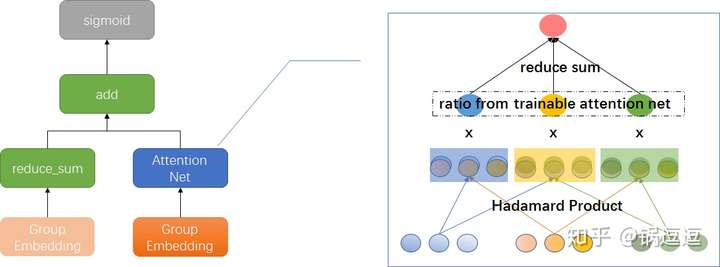
NFM 的改进,增加 attention 机制(pair-wise interaction + attention-based pooling),学习交叉相的权重,对无用的交叉项降权,减少噪声;同时可做重要性分析。
训练:先冻结 attension net 训练 FM embedding;然后固定 FM embedding 训练 attention net。
实现代码:
https://github.com/lambdaji/tf_repos/blob/master/deep_ctr/Model_pipeline/AFM.py
1 | with tf.variable_scope("Pairwise-Interaction-Layer"): |
论文在 MovieLens 数据集与 libFM / HOFM / Wide&Deep / DeepCross 算法对比,取得 SOTA 成绩。
DeepFM 17’
Huawei ICJA 2017
输入是高维、稀疏的、连续值离散值混合。
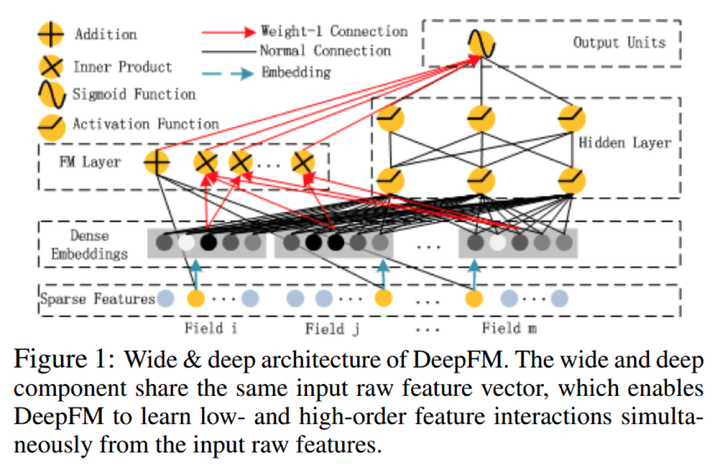
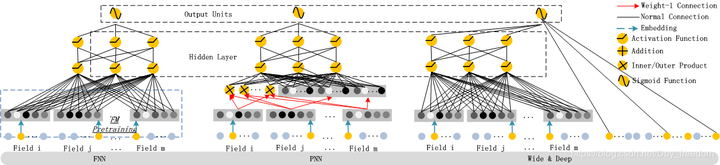
对比 FNN PNN W&D 网络结构
实现代码(省略 Dropout 和 BN)
https://github.com/lambdaji/tf_repos/blob/master/deep_ctr/Model_pipeline/DeepFM.py
1 | with tf.variable_scope("First-order"): |
xDeepFM 18’
KDD18 https://arxiv.org/pdf/1803.05170.pdf
腾讯广告比赛 19’ 冠军方案 https://zhuanlan.zhihu.com/p/73062485
论文在 Criteo 数据集与 DeepFM WDL PNN DCN 做对比,是目前 AUC 最好的方法。
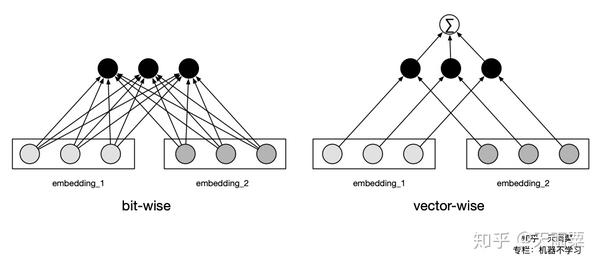
与 DCN 不同,DCN 在 cross 层进行 bit-wise 的有限高阶特征交叉,不区分 vector field 的概念;xDeepFM 在 CIN 层以 vector-size 进行有限高阶特征交叉。例如,Age Field对应嵌入向量<a1,b1,c1>,Occupation Field对应嵌入向量<a2,b2,c2>,在Cross层,a1,b1,c1,a2,b2,c2会拼接后直接作为输入,即它意识不到Field vector的概念。Cross 以嵌入向量中的单个bit为最细粒度,而FM是以向量为最细粒度学习相关性,即 vector-wise。xDeepFM的动机,正是将FM的vector-wise的思想引入Cross部分。
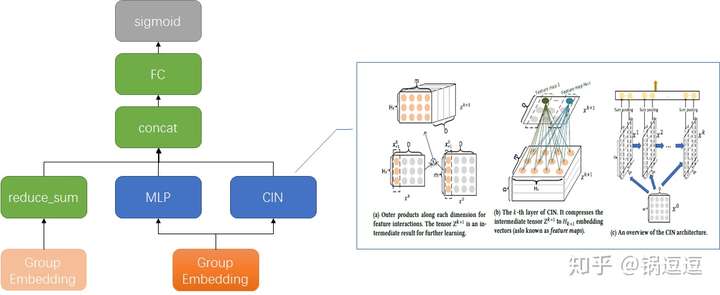
简而言之:xDeepFM 是实现 vector-wise、与上n层 的高阶特征交叉,DCN 每层是 bit-wise、与上一层 的高阶特征交叉。
https://zhuanlan.zhihu.com/p/57162373
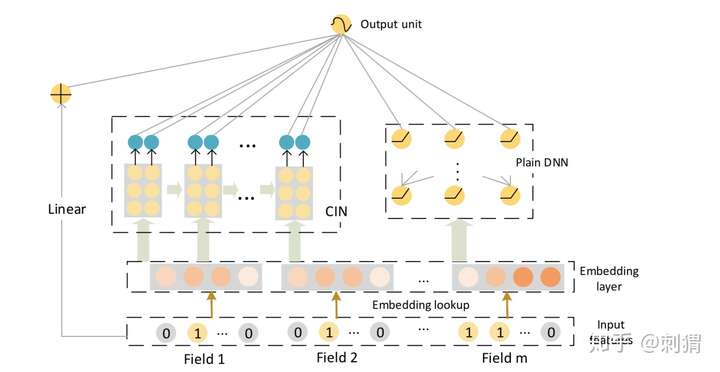
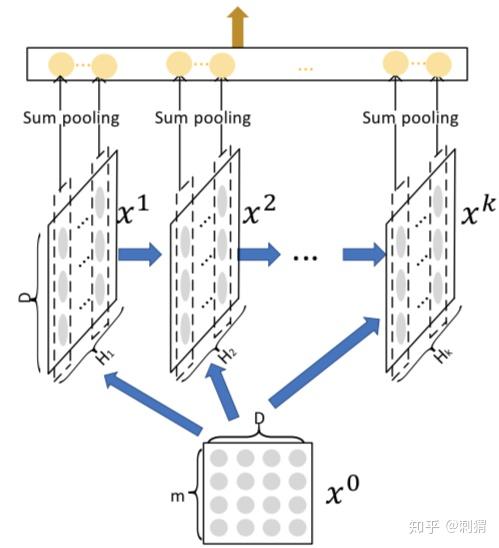
其中 CIN 结构下图,其中
是输入,由 m 个 field, D 维的 embbeding feature 组成。
表示第 k 层的输出, 表示 k 层的 vector 个数, 表示 hadamard 乘积(逐元素乘)
CIN与Cross的几个主要差异:
- Cross是bit-wise的,而CIN 是vector-wise的;
- 在第
层,Cross包含从 1 阶 ~
阶 的所有组合特征,而CIN只包含
复杂度
假设CIN和DNN每层神经元/向量个数都为 ,网络深度为
。那么CIN的参数空间复杂度为
,普通的DNN为
,CIN的空间复杂度与输入维度
无关,此外,如果有必要,CIN还可以对权重矩阵
进行
阶矩阵分解从而能降低空间复杂度。
CIN的时间复杂度就不容乐观了,按照上面介绍的计算方式为 ,而DNN为
,时间复杂度会是CIN的一个主要痛点。
https://zhuanlan.zhihu.com/p/57162373
双塔模型
DSMM 13’
是微软 2013 年发表的一个 query / doc 相似度计算模型,思想是将不同的对象映射到同一个语义空间中,利用语义空间中的距离计算相似度。
首先将 query 和 doc 转化成 embedding 向量 ,这里针对英文单词提出了 word hash 方法降低计算量(中文不适用)。
接着词向量 输入 DNN,选取 tanh 作为激活函数,得到 semantic feature ;然后 query 和 doc 会进行一次 cos 相似度计算得到 ,最后经过 softmax 得到 ,其中
损失函数
其中 是 query, 是点击 doc
DSSM

MultiView-DSSM
共享 item 参数

T-DSSM 16’
MV-DSSM 模型加入 user temporal feature,引入 attention 机制,学习用户的短期兴趣。
难点在于时序特征的设计和训练,使用前应权衡业务对时间序列预测的需求。

YoutubeNet 17
Youtube 在 Recsys 17 发表

相对于双塔结构,Youtube DNN 对物品 embedding、用户embedding 求平均然后 concat,用统一的(用户,物品)向量空间替代了原来的两个向量空间。

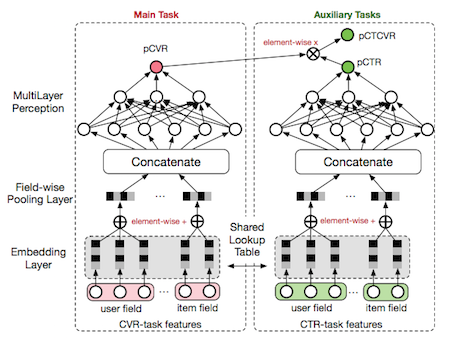
Entire Space Multi-Task Model 18’
阿里在 KDD18 提出,为了解决 CVR 预估中样本选择偏差和数据系数问题,提出在全局空间建模(通过 pCTCVR 和 pCTR 来优化 CVR)和特征 Transform 方法来解决。
损失函数定义
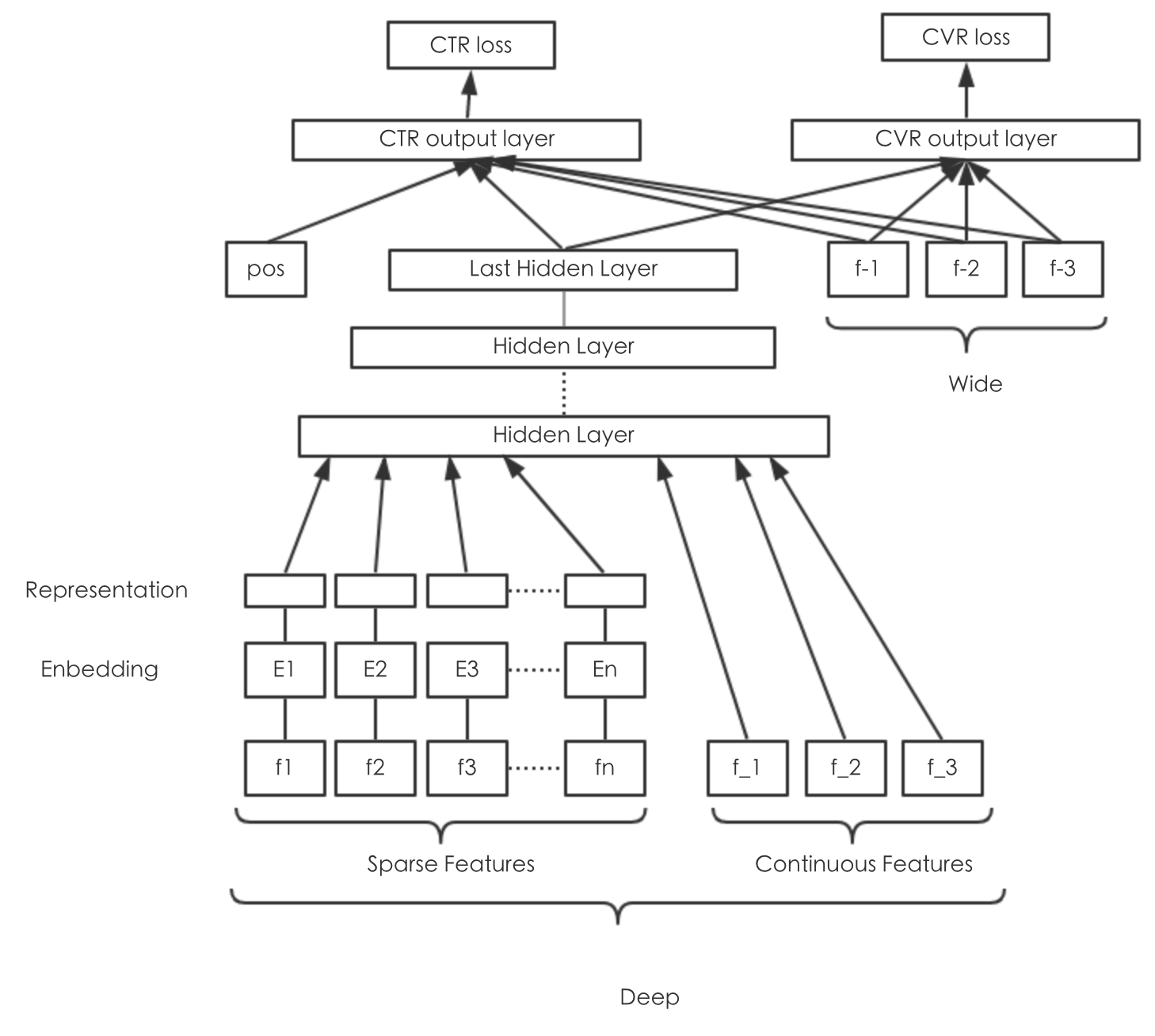
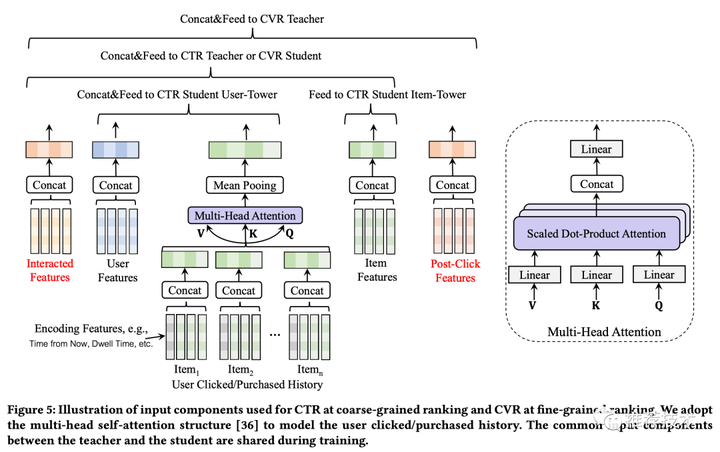
美团 Multi-Task Model
广告预估场景中存在多个训练任务,比如CTR、CVR、交易额等。既考虑到多个任务之间的联系,又考虑到任务之间的差别,我们利用 Multi-Task Learning的思想,同时预估点击率、下单率,模型结构如下图所示:
DIN 18’
阿里 KDD 2018 《Deep Interest Network for Click-Through Rate Prediction》
特点
- 引入用户购-商品历史的 Attention 机制
- dice 激活函数
对 用户 - 广告 有特征:
其中 A 是广告, 是用户特征, 是用户-商品序列。
函数 是 Activation Unit,把输入 拼接,输入 FC 层,输出权重 。
Activation unit 可以针对候选广告,对相关度较高的用户行为商品embedding,给出较高的权重,如下图所示:
https://www.infoq.cn/article/XA055tpFrprUy*0UBdCb
DIEN 19’
阿里 AAAI 2019 《Deep Interest Evolution Network》
- 引入循环网络(双层GRU),对用户历史事件序列建模,捕获用户兴趣演化
- 引入辅助 loss 帮助 GRU 学习
DMIN 20’
阿里 CIKM 2020 《Deep Multi-Interest Network for Click-through Rate Prediction》PDF
对用户行为切分 Session,使用自注意力建模 Session 的兴趣
https://mp.weixin.qq.com/s/Pn8kSSBuWq-6dULfDKQoSQ
TDM
CrossMedia 17’
a.k.a. Deep Image CTR Model
《Image Matters: Visually modeling user behaviors using Advanced Model Server CIKM 2017》 阿里 PDF
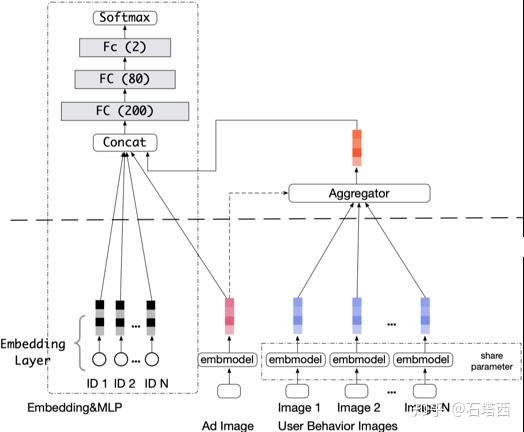
创新点:
- 将用户点击过的图像特征(与训练VGG的4096维输出)进行 attention pooling,对用户侧的视觉偏好建模(之前模型多用在物品侧)
- AMS 架构解决计算瓶颈
RNN CTR 19’
KDD19 Click-Through Rate Prediction with the User Memory Network
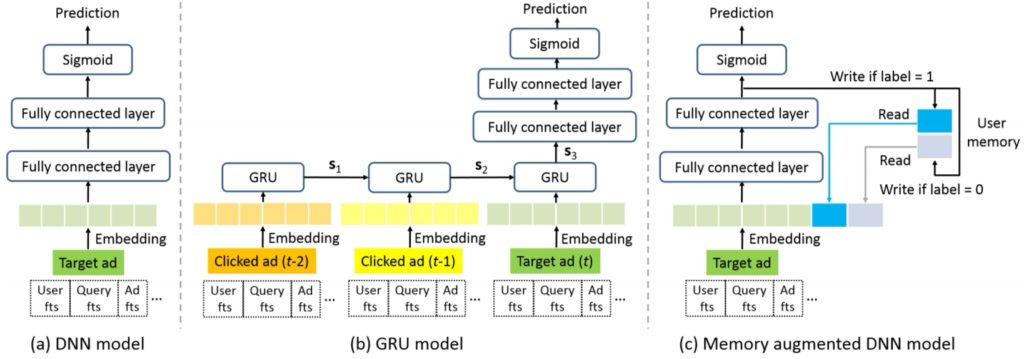
http://www.semocean.com/tag/embedding/
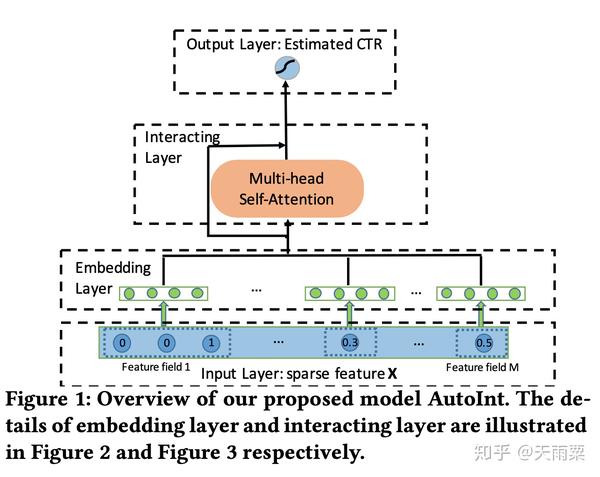
AutoInt 19’
《Automatic Feature Interaction Learning 2019》 PDF
相比于 DCN 和 xDeepFM 采用交叉网络 + DNN 的双路结构,AutoInt 直接采用了单路的模型结构,将原始特征Embedding之后,直接采用多层 Interacting Layer进行学习(作者在论文的实验部分也列出了AutoInt + DNN 的双路模型结构:AutoInt+);借鉴了NLP模型中 Transformer的 Multi-head self-attention 机制,给模型的交叉特征引入了可解释性。
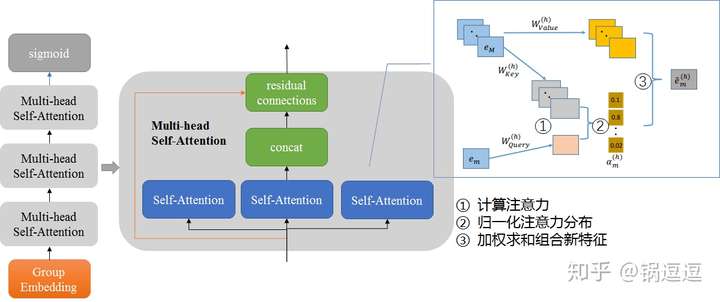
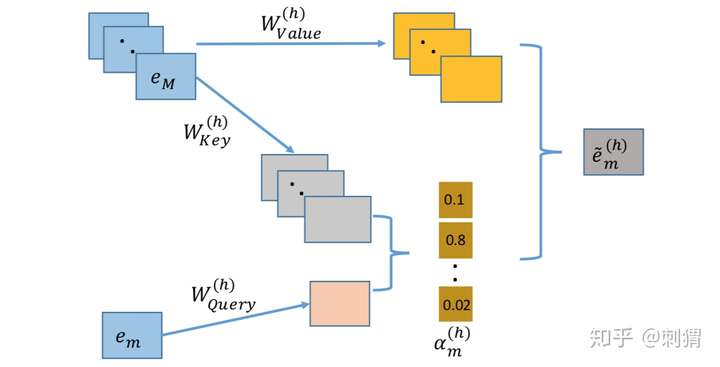
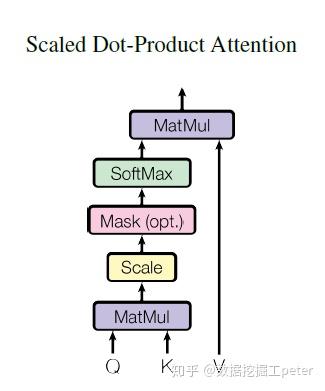
以上是 single-head self-attention 结构,multi-head 由多个以上结构派生。
其中:
\begin{align} \alpha_{m,k}^{(h)} &= \frac{\exp(\psi^{(h)}(e_m,e_k))}{\sum_{l=1}^M \exp(\psi^{(h)}(e_m,e_l))} \\ \psi^{(h)}(e_m, e_k) &=其中 是 emb 向量,把输入emb 向量 d 维空间映射到 d’ 维空间。
对每个输入向量 ,每个 single-head 输出,是 Query 和 Keyword 向量的加权和。
对每个输入向量 ,多个 single-head 输出,拼接得到 multi-head 的 :
加上恒残差连接加速训练:
其中 是投影矩阵,确保维度匹配。
把有输入向量的 multi-head res 输出向量 拼接起来,得到输出层:
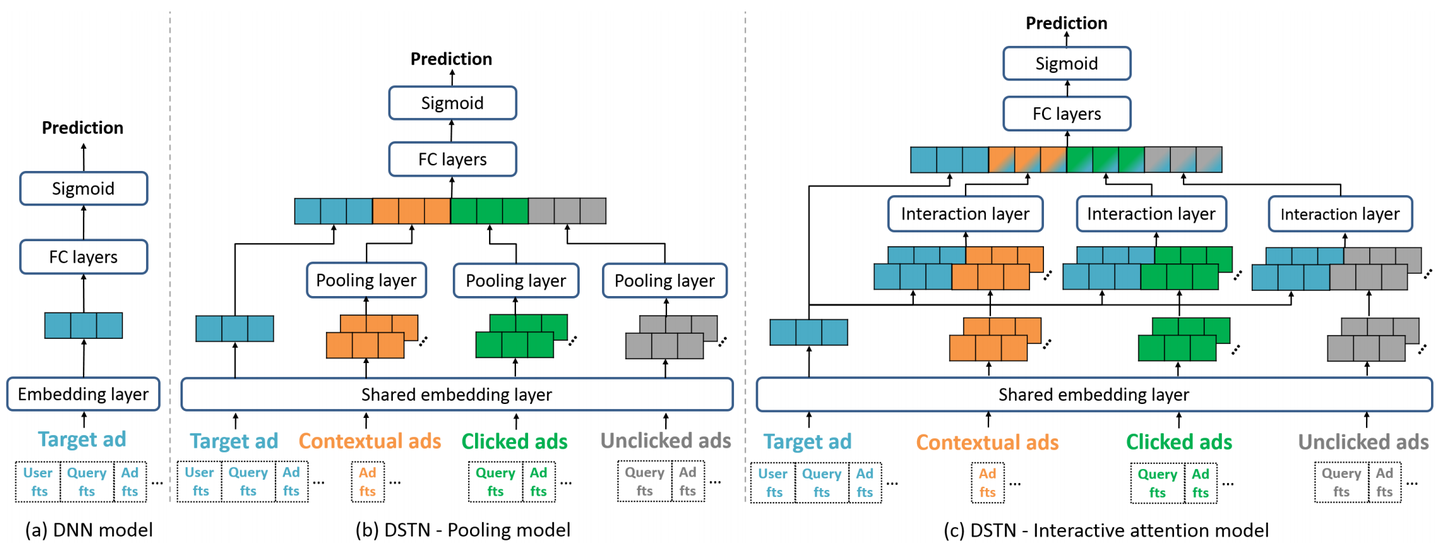
DSTN 19’
《Deep Spatio-Temporal neural Networks SIGKDD19》 PDF 阿里营销平台
b 模型,在 DNN 基础上,引入辅助广告特征:空域 — 同页的上下文广告;时域 — 最近点击未点击的广告。
c 模型,将目标广告的 embedding 和辅助广告一起输入到 attention 结构中,产生权重 pooling 起来,学习目标广告于辅助广告的重要性交互。
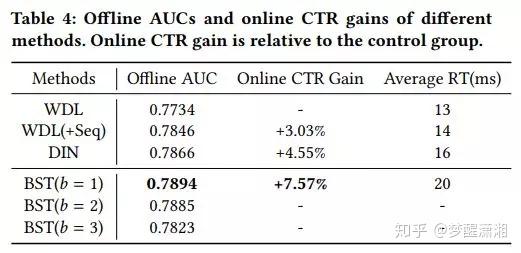
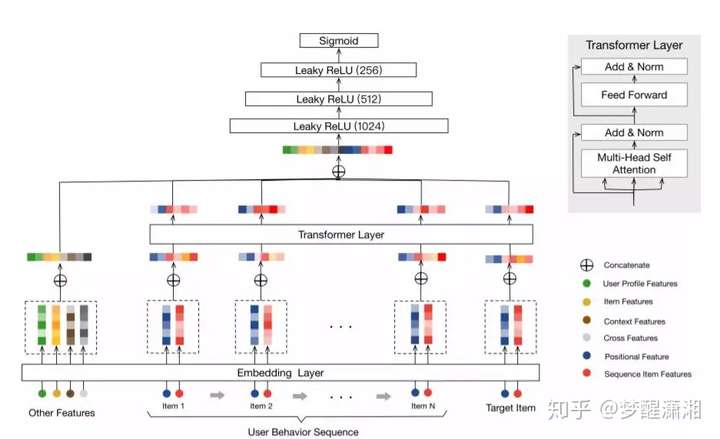
BST 19’
《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba 19》 PDF 阿里搜索推荐组
问题:DIN 没有捕捉用户行为的连续性。
通过 Transformer Layer(仅 Encoding 部分),学习用户行为序列 item 与候选 item 的特征表达,输入三层 MLP学习特征的交互,最后输入 sigmoid 输出概率。
注:Transformer 来自《Attention Is All You Need》,抛弃传统 NLP 任务的 RNN 和 CNN 结构,通过 Attention + MLP 结构完成 encoder decoder 任务,并且融合了位置信息。
注:item 输入特征中,蓝色是物品特征(只需取 item_id 和 category_id);红色是位置特征,模型学习位置编码(Positional Embedding)。
数据集合特点:用户行为丰富,淘宝 7 天数据,3亿用户,1千万物品,400亿样本,
效果:AUC 微小提升,CTR 显著提升
UMM
《Click-Through Rate Prediction with the User Memory Network DLP-KDD19》PDF git 阿里营销平台
DeepMCP
《Representation Learning-Assisted Click-Through Rate Prediction IJCAI19》PDF 阿里营销平台
传统的 DNN 模型将特征 embedding 用全连接网络往上送,最终和 label 一起计算 loss 并优化,学习时更多地关注 label 和特征之间的相互关系,虽然也有神经元连接起到交叉作用,但是特征和特征之间的相互影响学习的较少。比如某个用户点了某个 item,模型学习的结果并不要求用户和 item 表达有相似性。目前有些可借鉴的网络结构,如 DSSM,会要求两个输入 item 有一定的相似性。因此我们借鉴了这种思路,并将现有的模型结构融合起来,使得 DNN 网络学习的同时,对 Embedding 的学习也使用一些辅助网络来强化。对应到我们的业务中,如用户和广告,如果有点击关系,是否能相似一些,用户点击序列中的广告,是否能学的相似一些。
整个 DeepMCP 网络分为三个部分:一个是主网络,可以是任何的 DNN 网络结构,如 wide&deep,DeepFM;两个辅助网络:匹配子网络和关联子网络。匹配子网络学习的是用户和广告的相关性 ( 类似 DSSM ),关联子网络是学习广告和广告的相关性 ( 类似 word2vec 和 graph embedding ),目标是希望整个网络既有好的预测能力,又有好的 feature embedding 表达能力,从而提升模型的泛化能力。MCP 模型还有一个优点,线上 inference 时, 只需要把主网络激活就可以了,其它部分不需要计算,对线上计算性能没有影响。
《深度时空网络、记忆网络与特征表达学习在 CTR 预估中的应用》 秀武 阿里高级算法专家
UIC&MIMN 19
《Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction》PDF
MIMN借鉴了memory network的思想,用一个固定的memory矩阵对用户的兴趣信息进行存储。对于用户每一个新增的行为进行兴趣的encode后,写入其对应的memory slot中。在线计算某个用户CTR的时候使用当前最新的用户兴趣矩阵信息,在进行CTR的推断。这样的做法将长期兴趣建模和CTR预估两部分进行解耦,用户兴趣矩阵提前计算完毕,不会在对CTR预估计算带来latency瓶颈,同时在线需要通信和存储的内容也从原始行为序列变成了固定大小的memory矩阵。在这样的设计帮助下,我们实现了对1000量级的行为序列进行建模,并落地到了在线生产环境。但是这样的方案设计其实存在一些问题,其系统上带来的技术债暂且不表,算法上在目前的技术水平下存在一定的局限性。一个固定大小的memory 矩阵表达信息是有限的,如果我们想建模更长的用户行为序列,比如10000+,memory-based的方法会面临表达能力有限,难以过滤噪声,建模随时间信息遗忘的问题。UIC&MIMN解耦了兴趣建模和在线CTR预估的计算,建模用户兴趣时模型无法获取和使用待预估的候选item的信息。
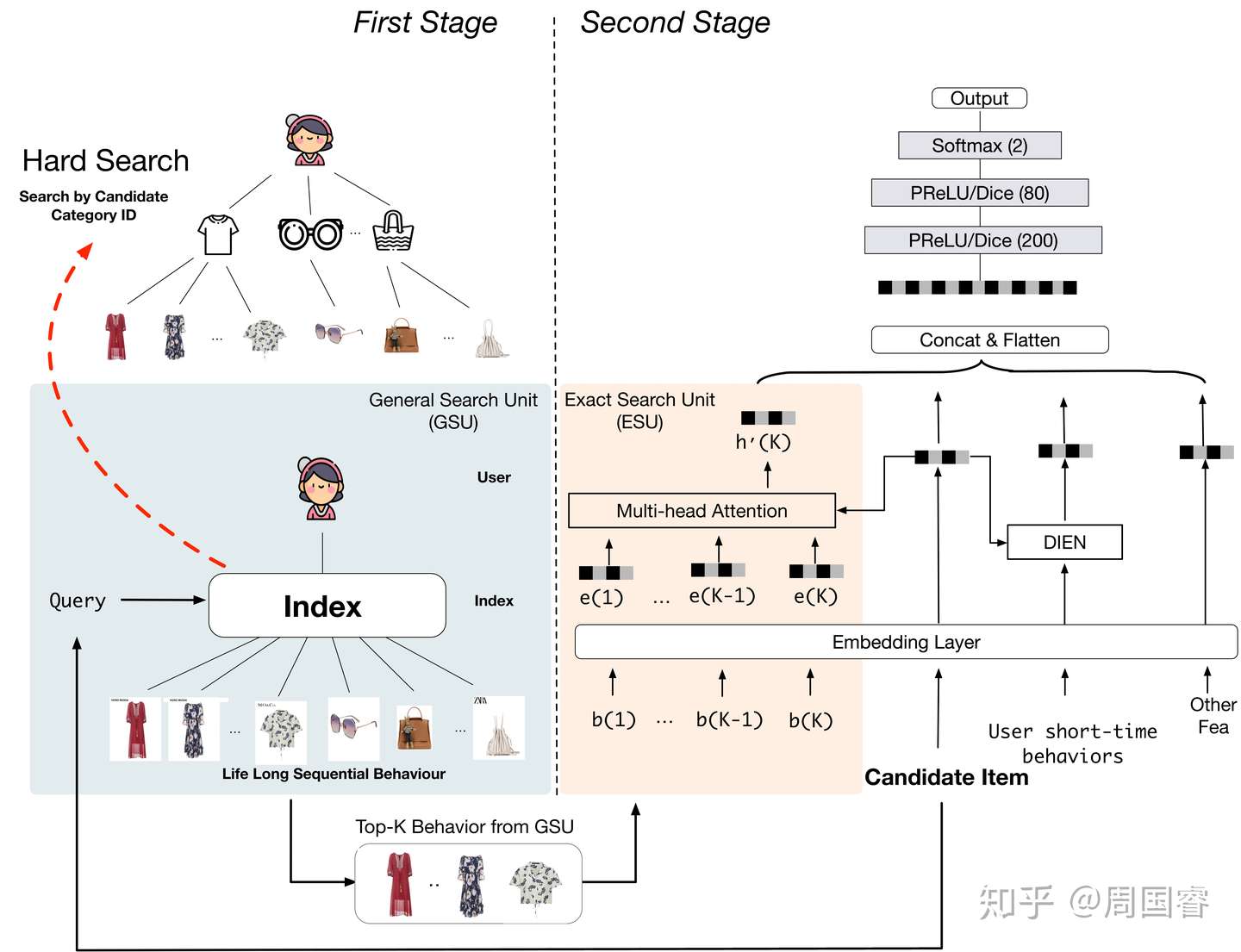
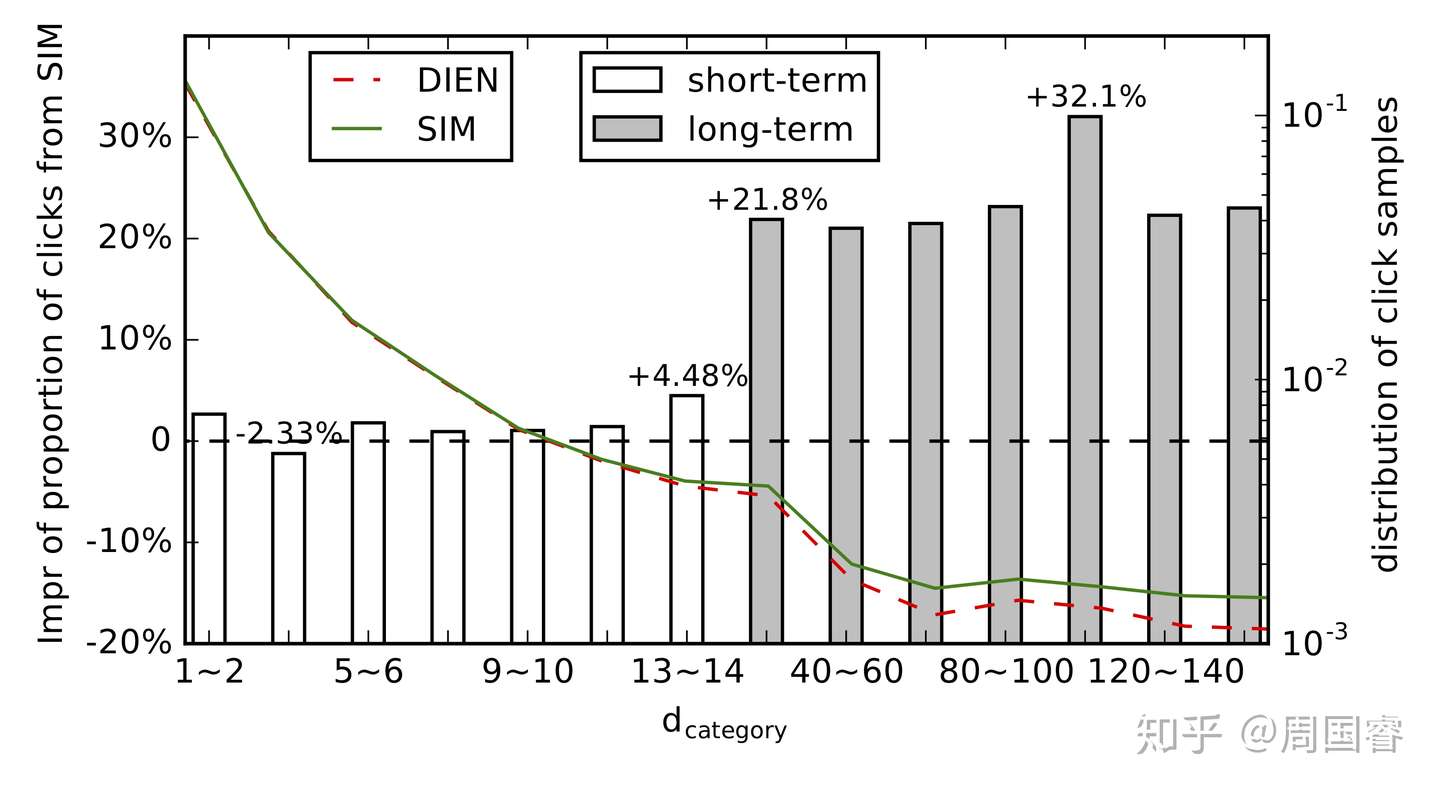
SIM 20
《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》KDD19 阿里 PDF
《Life-long兴趣建模视角CTR预估模型:Search-based Interest Model》周国睿 知乎
SIM 旨在研发一个可以根据预估目标item信息对用户全生命周期行为进行search,获取该item相关信息的方法。稳重提出了两阶段的search模式:general search 和 exact search。从精度角度我们将搜索拆解为一个相对粗糙普适的搜索和一个更为具体精确的搜索。
SIM 给出了一个通用的 framwork 让我们可以给每个用户的所有行为都构建一个索引,在预估CTR的时候可以充分的考虑用户的所有行为表达。
多任务学习
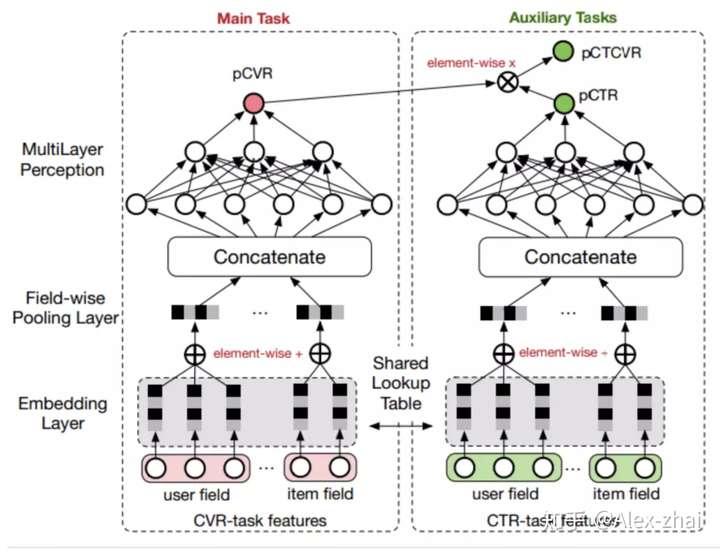
ESMM 18’
pCTR pCTCVR 任务辅助 pCVR 学习,缓解 pCVR 样本选择有偏(SSB)、数据稀疏(DS)的问题。
所有 user / item embedding lookup 结果,会 element-wise 加起来,再进行 concat,这样的设计利于特征扩展。
损失函数
Oversampling:把正样本复制多分,缓解 DS 问题;
AMAN:把 All Missing As Negative,通过引入未点击未转化样本,部分解决 SSB 问题;
UNBIAS:
DIVISION:
ESM^2
《Entire Space Multi-Task Modeling via Post-Click Behavior Decomposition for Conversion Rate Prediction》Ali arxiv2019 PDF
更多任务
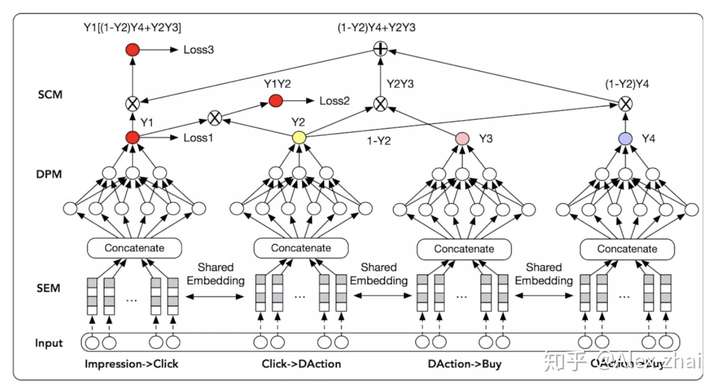
MoSE 20’
《Multitask Mixture of Sequential Experts for User Activity Streams》Google KDD2020 PDF 深度传送门
本文主要研究了如何在多任务学习场景中针对用户行为序列进行建模,提出了一套新颖的模型框架 MoSE(Mixture of Sequential Experts)。在当前最新的MMoE多任务学习框架中使用LSTM针对用户行为序列进行显式建模。同时,本文也通过离线实验以及GMail的线上实验证明了本文的有效性。
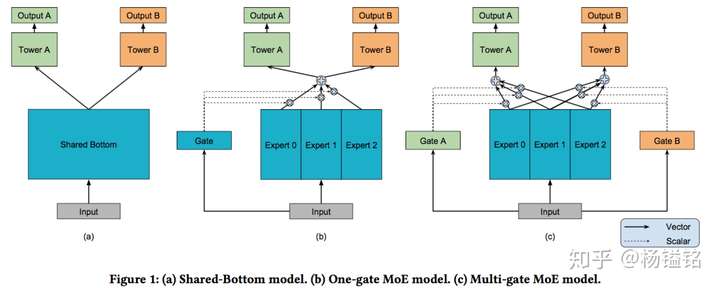
MMoE 18’
《Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts KDD18》PDF
多任务学习常见结构:share-bottom 共用隐层,参数少,避免过拟合,但子任务差异很大效果不佳。
论文提出 MMoE 结构,通过 multi gates 和 mult experts,学习每类任务的表达,解决 shared-bottom 子任务差异大效果不佳的问题。
与 ESMM 不同,子任务之间无关联。
SNR 19’
《SNR: Sub-Network Routing for Flexible Parameter Sharing in Multi-task Learning AAAI19》PDF
解决多任务学习问题,任务间相关性低时,shared-bottom 或 MMoE 等方法精度不高的问题。
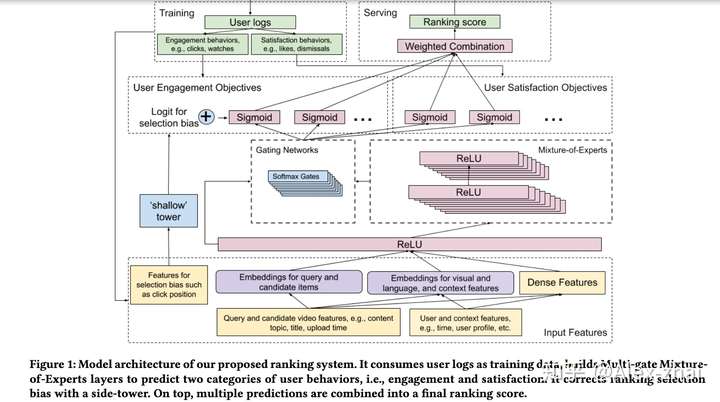
YouTube Multitask Ranking System
《Recommending What Video to Watch Next: A Multitask Ranking System RecSys19》 PDF
解决:
- MMoE 视频推荐中的多任务目标:比如不仅需要预测用户是否会观看外,还希望去预测用户对于视频的评分,是否会关注该视频的上传者,否会分享到社交平台等。
- Shallow Tower 预测偏置位置信息,输入 pCTR 任务:比如用户是否会点击和观看某个视频,并不一定是因为他喜欢,可能仅仅是因为它排在推荐页的最前面,这会导致训练数据产生位置偏置的问题。
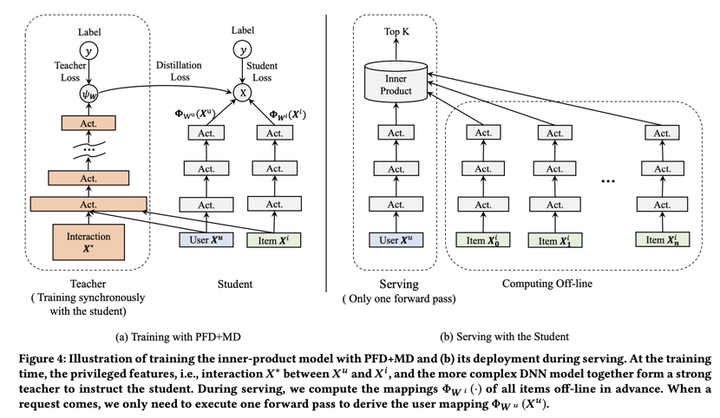
PFD 20’
《Privileged Features Distillation at Taobao Recommendations KDD20》 PDF
损失函数
其中 是 student、teacher 模型原始 loss, 是 student、teacher 模型的预估值。 是普通特征+优势特征, 是普通特征。
蒸馏方法通常训练老师,再固定老师权重训练学生;为加速,两个模型同时训练,通过调整 先重点训练 teacher 模型,再逐渐增加 权重。
淘宝推荐系统架构
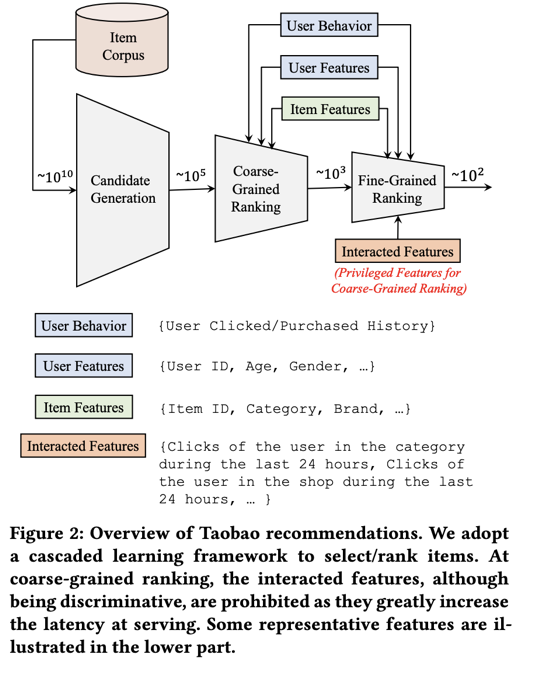
统一蒸馏:MD(模型蒸馏)与 PFD(优势特征蒸馏)结合,用精排 CTR 模型做老师,粗排模型做学生
UW Loss 18’
《Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics CVPR18》PDF
与固定权重损失 相比,UW Loss 的权重是通过最小化损失函数学习得到的。
推导:令 为神经网络的输出值,定义概率模型(回归)
定义概率模型(分类)
定义多任务 likelihood
回归模型的多任务 log likelihood (Gaussian likelihood,假设概率模型服从高斯分布)
对两个回归任务 ,损失函数为
\begin{align} L(W,\sigma_1,\sigma_2) &=-\log p(y_1,y_2|f^W(x)) \\ &\approx \frac{1}{2\sigma_1^2}||y_1 - f^W(x)||^2 + \frac{1}{2\sigma_2^2}||y_2 - f^W(x)||^2 + \log \sigma_1 \sigma_2 \\ &= \frac{1}{2\sigma_1^2} L_1(W)+\frac{1}{2\sigma_2^2} L_2(W)+\log \sigma_1 \sigma_2 \end{align}对比固定权重损失
帕累托最优
《A Pareto-Efficient Algorithm for Multiple Objective Optimization in E-Commerce Recommendation RecSys19》PDF
如何用模型自动寻找最优的目标权重参数组合,就是一个非常有价值的方向,目前最常用的方式是采用帕累托最优的方案来进行权重组合寻优,这是从经济学引入的技术方案,未来还有很大的发展空间。
多模态信息融合
加入 user / item 侧的音视频特征、图片特征。难点在于工程支撑,如何设计结构获取有效的特征表示。
《Collaborative Multi-modal deep learning for the personalized product retrieval in Facebook Marketplace》
《Image Matters: Visually modeling user behaviors using Advanced Model Server》
实现
https://github.com/guoday/ctrNet-tool (tensorflow layer API, criteo 数据集 dense 格式)
https://github.com/shenweichen/DeepCTR (tensorflow keras API)
https://github.com/nzc/dnn_ctr (pytorch)
https://github.com/lambdaji/tf_repos/tree/master/deep_ctr (tensorflow-1.12 Pyhton2.7 Estimator API,criteo 数据集 libsvm 格式,支持 TFServing 模型导出)
https://github.com/lambdaji/tf_repos/tree/master/DeepMTL (ESMM tensorflow-1.12 Pyhton2.7 Estimator API ESMM,天池数据集,支持 TFServing 模型导出)
Reference
https://zhuanlan.zhihu.com/p/40135103
深度学习在美团搜索广告排序的应用实践 https://tech.meituan.com/2018/06/07/searchads-dnn.html
远程监督 https://blog.csdn.net/m0_38031488/article/details/79852238
2019 腾讯广告冠军方案 知乎
推荐系统中的注意力机制——阿里深度兴趣网络(DIN)知乎
DeepCTR:易用可扩展的深度学习点击率预测算法包 知乎
TODO
漫谈深度学习时代点击率预估技术进展 朱小强 InfoQ
MLR 阿里妈妈算法团队
详解阿里之Deep Interest Evolution Network(AAAI 2019) 知乎
CTR预估模型发展过程与关系图谱 知乎
NLP 中的 Transformer 和 BERT 知乎
