Q 分布
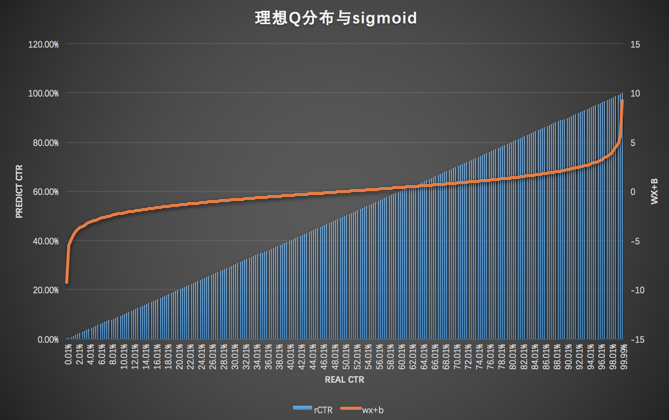
Q 分布图:横轴 realCTR 纵轴 pCTR
保序:Q分布图是直线,样本排序正确
保距:45度,样本等距
评估指标
AUC
如果不考虑校准,AUC 是不错的指标。在生产环节,我们希望 pCTR 更接近实际 CTR,而非仅仅给出正确的 ranking order,避免 under-delivery 或者 over-dilivery。
NE
Normalized Entropy / Normalized CrossEntropy / Normalized Logarithmic
Loss,用样本 CTR 的交叉熵归一化 pCTR 的交叉熵。当 background CTR 越接近 0 和 1 时交叉熵会更好,加上分母使得 NE 指标不受 background CTR 影响
其中 是标签, 是预测值, 是经验 CTR。
Calibration
calibration = average estimated CTR / empirical CTR
负例子降采样

Re-Calibration
等比推算
其中 q 是校准后的预测值,p 是降采样后的模型预测值,w 是负样本降采样率
推导方法:正样本数 a,负样本数 b,正样本采样率 l,负样本采样率 m,有
\begin{align} p&=\frac{a}{a+b}\\ q&=\frac{la}{la+mb}=\frac{a}{a+wb}\\ w&=\frac{l}{m} \end{align}Isotonic fit (保序回归)

https://scikit-learn.org/stable/modules/calibration.html
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.isotonic
Facebook 在线模型

TEG 推荐架构

