假设检验
基本步骤
- 提出原假设 和备择假设
- 考虑检验中对样本做出的统计假设;例如,关于独立性的假设或关于观测数据的分布的形式的假设
- 确定适当的检验统计量 wiki
- 在零假设下推导检验统计量的分布。在标准情况下应该会得出一个熟知的结果。比如检验统计量可能会符合 t-分布 或 正态分布
- 选择一个显著性水平 ,若低于这个概率阈值,就会拒绝零假设。常用 5% 和 1%
- 根据在零假设成立时的检验统计量 分布,找到数值最接近备择假设,且几率为显著性水平 的区域,此区域称为“拒绝域”,意思是在零假设成立的前提下,落在拒绝域的几率只有
- 针对检验统计量 ,根据样本计算 / 查表得到其估计值 和
- 若估计值 落在“拒绝域”(如 ),接受对立假设;反之接受零假设
检验统计量
检验统计量, test Statistic wiki,是一个从样本推导出来的统计量,用于假设检验。
Chi-Square Test
适用问题:统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越小;反之,二者偏差越大,若两个值完全相等时,卡方值就为0,表明理论值完全符合。其中卡方检验针对分类变量。
例:两组数据转化率是否一致?男性、女性对线上买生鲜食品的行为有没有区别?
ANOVA F-test
ANalysis Of VAriance,方差分析,又称变异数分析,F-test。
适用问题:判断两组来自正态分布总体的样本,方差是否相同。
一般在双样本 T-test 前使用:若两总体方差相等,则直接用 t-test;若不等,可采用 Welch’s t-test 或变量变换或秩和检验等方法。
1 | import scipy.stats |
如果样本非来自正态分布总体,可以使用 Levene’s test or Bartlett’s test 算法。
Z-test
适用问题:两组大样本(大于30)正态分布数据, 均值之差是否为某一实数。
原理:用标准正态分布的理论来判断差异发生的概率,从而比较两个平均数>平均数的差异是否显著。
例:王者荣耀男性、女性用户,人均付费是否有显著差异?
T-test
适用问题:【一组 | 两组】来自正态分布总体的独立样本,其中样本数小于 30 或方差未知,其 【均值 | 均值之差】是否为某一实数。
t-test 改进了 z-test 在样本量小于 30 时误差大的问题。
假设 是正态分布的随机变量,其中样本为 ,均值是 ,方差是 ,均未知。
样本均值为
样本方差 (Bessel-corrected) 为
以下随机变量服从均值为 0 方差为 1 的正态分布
单总体情况,t 统计量定义为
双总体情况,t 统计量定义为
应用1
给定样本:算法 A / B 流量下的用户付费情况
提出假设: 算法 B 与算法 A 人均付费一致
计算:样本的 统计量 ;给定显著水平(置信度) (如 95%),自由度 ( 为样本数),查表得到 。
结论:如果 ,我们有理由拒绝原假设。
应用2
For example, given a sample with a sample variance 2 and sample mean of 10, taken from a sample set of 11 (10 degrees of freedom), using the formula
we can determine that at 90% confidence, we have a true mean lying below 10.58 and over 9.41.
In other words, on average, 80% of the times that upper and lower thresholds are calculated by this method, the true mean is both below the upper threshold and above the lower threshold. This is not the same thing as saying that there is an 80% probability that the true mean lies between a particular pair of upper and lower thresholds that have been calculated by this method.
应用3
1 | import scipy.stats |
最小样本数估算
二项分布 p 的置信区间
对二项分布 ,
其中 对于 95% 显著水平或置信度,。
二项分布假设检验
TODO http://pages.stat.wisc.edu/~st571-1/10-power-4.pdf
应用1:双样本最小样本计算
样本1 转化率 1%,样本2 转化率 1.5%,sig.level 为 ,power 为 ,求最小样本量
1 | power.prop.test(n=NULL, p1=0.01, p2=0.015, sig.level=0.05, power=0.95, alternative = "two") |
应用2:单样本最小样本计算
样本1 转化率 1%,sig.level 为 ,power 为 ,求最小样本量
1 | install.packages('pwr') |
应用3:在线计算器
https://www.stat.ubc.ca/~rollin/stats/ssize/b1.html
原假设 H0:希望推翻的假设
备选假设 H1:希望验证的假设
| 判断\实际 | 没区别 H0 | 有区别 H1 |
|---|---|---|
| 有区别 | 一类错误, Sig. Level | Statisic Power |
| 没区别 | 二类错误 |
Statistical Power ()统计学功效:在假设检验中, 拒绝原假设后, 接受正确的替换假设的概率。在假设检验中有 错误和 错误。 错误是 FP 错误, 错误是 FN 错误。
Significiant Level 显著性水平 。同时也是 Type I Error 出现的概率,FP,第一类错误意味着新的产品对业务其实没有提升,我们却错误的认为有提升。
Minimum Detectable Effect 最小改善程度
样本方差 ,在二项分布中
求实验组的最小样本
https://jeffshow.com/caculate-abtest-required-sample-size.html#more-1798
https://www.cnstat.org/samplesize/11/
http://www.evanmiller.org/how-not-to-run-an-ab-test.html
http://www.evanmiller.org/ab-testing/sample-size.html
https://zhuanlan.zhihu.com/p/40919260
Two-porportion
TODO 公式推导 https://select-statistics.co.uk/calculators/sample-size-calculator-two-proportions/
P-value
p 值是指在一个概率模型中,统计摘要(如两组样本均值差)与实际观测数据相同,或甚至更大这一事件发生的概率[1] 。换言之,是检验假设H0成立或表现更严重的可能性。p值若与选定显著性水平(0.05或0.01)相比更小,则H0会被否定而不可接受。然而这并不直接表明原假设正确。通常在H0设下,p值是一个服从[0,1]区间均匀分布的随机变量,在实际使用中因样本等各种因素存在不确定性。产生的结果可能会带来争议。
效应量
在统计学中,效应值(effect size,或译效果量)是量化现象强度的数值。[1]效应值实际的统计量包括了二个变数间的相关程度、回归模型中的回归系数、不同处理间平均值的差异……等等。无论哪种效应值,其绝对值越大表示效应越强,也就是现象越明显。效应值与特效检验的概念是互补的。在估算统计检定力、需要的样本数与进行元分析时,效应值经常扮演重要角色。
在研究结果中报导效应值被视为洽当的或必须的。[2][3]相对于统计学上的显著性,效应值有利于了解研究结果的强度。[4]特别是在社会科学和医学研究上,效应值更显得重要。绝对与相对效应值可以传递不同的讯息,又可互相补充讯息。
| Effect size | d[5] | r[6] |
|---|---|---|
| 较小 | 0.2 | 0.10 |
| 中等 | 0.5 | 0.30 |
| 较大 | 0.8 | 0.50 |
参数估计:正态总体
假设:已知样本 来自正态分布总体 ,参数 未知。
参数估计:
- 点估计(矩法 / 极大似然法):求得参数
- 区间估计:求置信系数为 p 的参数区间
例子:工厂生产零件的长度 X 服从正态分布 ,随机抽取 6 个样本,长度为 [14.6, 15.1, 14.9, 15.2, 15.1],求置信系数为 0.95 的零件长度区间估计、方差区间估计
1 | import scipy.stats |
参考
https://www.zhihu.com/question/309884517
t-统计量表
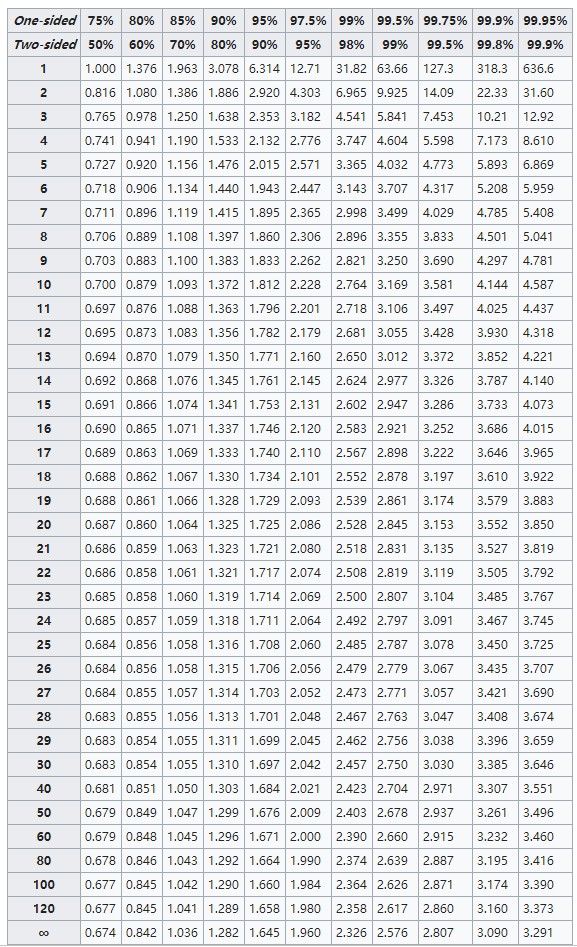
https://www.statisticshowto.datasciencecentral.com/z-alpha2-za2/
