Network Embedding
Item2vec
Barkan et. al. 在 ICML16 Workshop 提出,区别于 item2item (ALS ItemCF)方法,用 word2vec (负采样 Skip-gram) 学习物品隐式表达。
以用户浏览商品作为句子。假设同句子中的词是无顺序关系的,忽略了浏览顺序的 spartial information。其他情况可能不符合该假设,比如丛书《哈利波特1-5》。
Music 领域分类,用音乐人流派进行聚类, item2vec 方法与 SVD 对比,有效分类:

Airbnb Embedding
KDD 18 Real-time Personalization using Embeddings for Search Ranking at Airbnb (Airbnb 2018)
对用户和房源计算 word2vec,embedding everything,提升搜索推荐系统的性能。
Graph Embedding
目标是用低维稠密向量表示图中的点。解决传统方法问题:
- 矩阵分解 — 计算量大
- 构造人工特征 — 需要领域知识、工作量大
可用于推荐、节点分类、链接预测、可视化等场景。
DeepWalk
刻画节点在图上的近邻性 —— 在 1- W步的随机游走过程中,两个节点能到达的概率。
构造无向无环图,以特定点作为起点,做随机游走得到点的序列作为句子,用 w2v skip-gram 学习。
例如给定 KV 对(用户,APPID),计算 APPID 的 embedding 时,以 APPID 作为节点,两个 APPID 之间共同的用户占比作为权重。

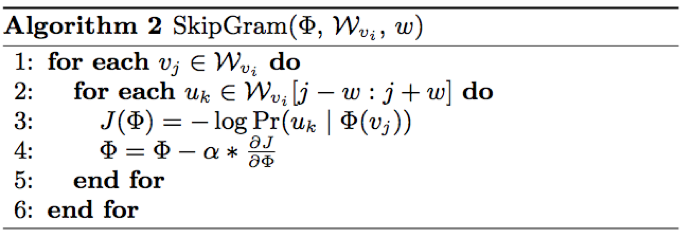
LINE
《LINE: Large-scale Information Network Embedding WWW15》MSRA PDF
是 DeepWalk 仅游走 1 、2 步的带权重版本,为性能考虑做了一些优化。
利用图中已存在的边构造目标函数,该目标函数显式描绘了一阶(6 和 7)和二阶(5 和 6)的邻近关系。然后通过优化方法去学习点的表达向量,其本质上是一种关于边的平滑,即很多很可能存在的边实际上不存在,需要模型去学习和预测出来。

一阶优化目标
对每一条无向边 ,定义顶点 的联合概率为
其中 为 的低维向量表示, 是边权。
同时定义经验分布
优化目标为
其中 是两个分布的距离,常用 KL 散度。设 p 为真实分布,q 为近似分布, KL散度是用来度量使用基于 q 的分布来编码服从 p 的分布的样本所需的额外的平均比特数:
如果使用 KL 散度并忽略常数项,则有
二阶优化目标
这里对于每个顶点维护两个embedding向量,一个是该顶点本身的表示向量,一个是该点作为其他顶点的上下文顶点时的表示向量。
对于有向边 ,定义给定顶点
条件下,产生上下文(邻居)顶点
的概率为
定义经验分布
其中 是边权, 是定点 的出度。对于带权图,有
优化目标为
其中 为控制节点重要性的因子,可以通过顶点的度数或者 PageRank 等方法估计得到。
带入 KL 散度并设 ,忽略常数项,有
对于 用户ID-游戏ID 序列能够较好的建模。
https://zhuanlan.zhihu.com/p/56478167
Node2Vec
Standford16,在 DeepWalk 的基础上更进一步,通过调整随机游走权重的方法使 graph embedding 的结果在网络的 同质性(homophily)和结构性(structural equivalence)中进行权衡。
为了使 Graph Embedding 的结果能够表达网络的同质性,在随机游走的过程中 BFS 产生结构性,DFS 产生同质性。为了获取二者的特性,通过 1/p 和 1/q 参数控制随机游走过程往远处跳、跳回的概率。
从实验结果看,同质性相同的物品很可能是同品类、同属性、或者经常被一同购买的物品,而结构性相同的物品则是各品类的爆款、各品类的最佳凑单商品等拥有类似趋势或者结构性属性的物品。
Metapath2vec
改进 LINE,通过 metapath,解决以构图在多种类型节点之间保存上下文概念,目标函数
其中 表示顶点 的邻居(第 类型), 是 softmax 函数。
在 Metapath2vec 中,softmax 函数是在所有节点无论什么类型上进行归一化:
在 Metapath2vec++ 中,softmax 函数是在相同类型节点上进行归一化:
为加速运算,用 Heterogeneous negative sampling 优化,目标函数:
https://zhuanlan.zhihu.com/p/32598703
BiNE
《BiNE: Bipartite Network Embedding SIGIR18》 PDF
当尝试把 DeepWalk 方法应用于二部图上时,会出现两个问题:
- DeepWalk算法适用于同质网络,而二部图则是一个天生的异质网络,二部图的边连接了左右两种不同类型的节点。同时,目前的网络嵌入方法基本没有考虑去建模图中的隐式关系。
- DeepWalk的随机游走策略限制了对数据的采样,一是以每个节点为起点的游走序列的数量都相同,二是得到的这些序列的长度也都是相同的,这样会导致采集来的数据的分布与真实的数据分布会存在差异,如下图所示
虽然目前也有应用于异质网络上的模型如 metapath2vec,且我们可以认为二部图是一种特殊的异质网络,但这些模型也都有缺陷,比如metapath2vec++,它视显式关系与隐式关系在节点表示学习中同等重要,这点与我们的常识相悖,一般来讲,显式关系的重要性是要大于隐式关系的。
论文提出的BiNE模型首先进行有目的性的随机游走(random walk),生成节点序列。然后设计一种既考虑了显式关系(explicit relations),又考虑到了隐式关系(implicit relations)的新型优化框架,来学习节点的表示。
显式关系,就是指能从数据集中直接获得的关系信息,如图中可观测到的边的信息。
隐式关系,就是指数据中隐含的关系信息,例如两个节点间虽然并没有边相连,但它们连接了同一个节点,我们就有理由认为这两个节点之间存在着某种隐式关系。
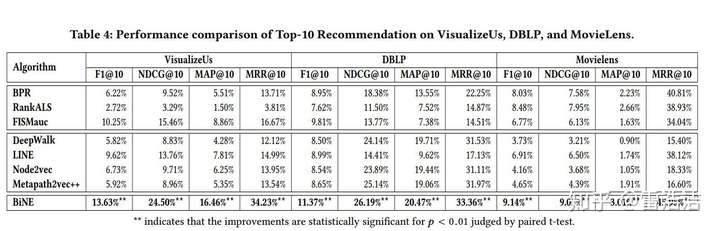
实验结果:BiNE 优于 LINE 和 metapath2vec++
https://zhuanlan.zhihu.com/p/83412062
M2GRL
《M2GRL: A Multi-task Multi-view Graph Representation Learning Framework for Web-scale Recommender Systems KDD2020》PDF
EGES
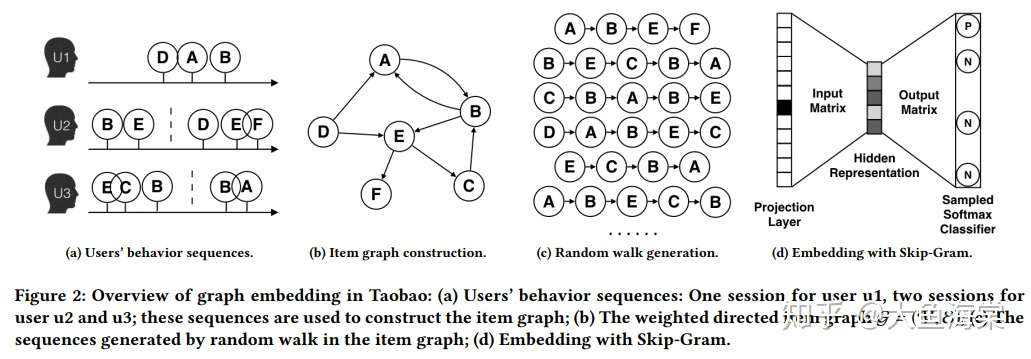
KDD18 Enhanced Graph Embedding with Side Information,为了使“冷启动”的商品获得“合理”的初始Embedding,阿里团队通过引入了更多补充信息 (side info) 来丰富Embedding信息的来源,从而使没有历史行为记录的商品获得Embedding,模型演进 DeepWalk -> BGE -> GES -> EGES。
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
BGE
通过 user 短期行为序列构建有向有权图,节点是 item,通过 Skip-Gram 学习 embedding。
GES
在 BGE 基础上,加入 item 的额外信息(category brand price 等)作为 words,通过 Skip-Gram 训练得到 embedding。
对每个 item,有 item_emb / cat_emb / bran_emb / price_emb,用这些 embedding 均值作为 item 的表达。
EGES
在 GES 基础上,引入了 attention 机制,对每个 dense embedding 增加可训练的权重,并做 softmax 归一化
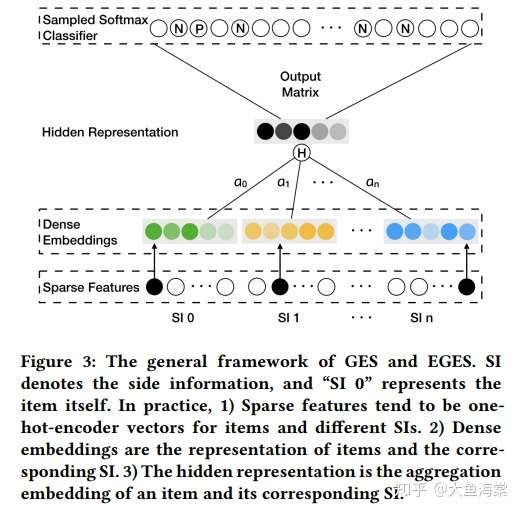
应用 Weighted Skip-Gram 方法学习模型参数。

https://blog.csdn.net/google19890102/article/details/108863046
SDNE
THU16 本文认为,DeepWalk 的缺点是缺乏明确的优化目标,即objective function,而LINE是把网络的局部信息和全局信息分开学习,最后简单地把两个表达向量连接起来,显然不是最优做法,文章利用深度学习去做graph embedding,好处自然是非线性表达能力更强了,然后设计了一个同时描述局部和全局网络信息的目标函数,利用半监督的方式去拟合优化。
SimRank
MIT 02 Jeh & Widom 提出,给定 user-item 二部图 ,考虑如果用户相似,那么他们关联的物品也相似。其中 V 是节点,E 是边。
定义两个节点的相似度
如果 a = b 则 ;如果 则结果如上式;其他情况
其中 表示和 a 相连的二部图另一个子节点的集合。
SimRank++
SimRank++算法对SimRank算法主要做了两点改进。第一点是考虑了边的权值,第二点是考虑了子集节点相似度的证据。
User2vec LSTM
Graph Conv Network
https://zhuanlan.zhihu.com/p/74345718
GraphSAGE
《Inductive Representation Learning on Large Graphs NIPS17》PDF
https://zhuanlan.zhihu.com/p/62750137
https://zhuanlan.zhihu.com/p/74242097
图网络内节点表达的学习,已在多项任务中被证明了其实用性,如传统的Deepwalk、Semi-GCN等方法。但是,目前大多数已存在的方法,在训练过程中都仅仅考虑当前的节点,学习目标也是直接生成当前节点的embedding,而对未知的节点,并不能起到泛化的作用。也就是说,目前的大部分方法,都是transductive式学习。
为了解决对未知节点的泛化问题,本文提出了GraphSAGE的方法,它采用的是inductive的学习模式,在GCN基础上,通过训练聚合邻居节点的函数,使得GCN扩展成inductive学习的任务,对未知节点起到泛化作用。
http://km.xx.com/group/24938/articles/show/404557
斯坦福大学的JureLeskovec团队在NIPS017提出了GraphSage 模型,通过以下两方面的改进来解决掉上述原始GCN的两个缺陷:(1)不是直接对全图进行卷积,而是通过对目标节点的邻居进行随机采样得到子图,再对子图进行卷积,大大降低了计算和内存的压力。(2)不是直接学习网络节点的embedding,而是学习一个聚合函数(aggregator),这个聚合函数能够把邻居节点的特征聚合到中心节点的身上。当我们学习出聚合函数后,就可以泛化到新的节点或者新的网络上,即使是在训练过程中模型没有见过的节点也能推断出其embedding,是一种归纳式(inductive)学习算法。GraphSage的算法架构如下图所示分为三个步骤:
- 对图中的每个节点采样固定数量的邻居节点作为该节点的邻居节点集合。
- 通过模型学习的聚合函数(aggregator)对步骤1中采样得到的邻居节点集合进行聚合,把邻居集合节点的特征信息聚合到中心节点上,得到新的节点Embedding。
- 由步骤2邻居聚合得到的新的节点embedding用来进行下游的预测任务。
GAT
《GRAPH ATTENTION NETWORKS ICLR18》 PDF
GraphSAGE 在聚合邻居节点过程中,将其都视作相同的贡献度有些粗糙与不合理,因此本文引入注意力机制到图神经网络中,每一层学习节点的每个邻居对其生成新的特征的贡献度,按照贡献度大小对邻居特征进行聚合,以此来生成新的聚合特征,供下游任务使用。
H-GCN
《Hierarchical Graph Convolutional Networks for Semi-supervised Node Classification 19》PDF
GCN的相关方法尽管在网络挖掘任务中取得了巨大成功,但大多数基于邻居聚合特征的方法,通常层数都比较浅,且缺乏graph pooling的机制,使得其很难获得充足的网络的全局信息。因此,为了扩大卷积层的感受野,本文提出了深度层次的GCN网络来机型semi-supervised的节点分类任务。(由于超点对应了原始图的局部结构,对超节点组成的超图进行卷积,也就获得了更大的感受野)
GraphRT
《Graph Neural Network for Tag Ranking in Tag-enhanced Video Recommendation CIKM20》PDF
https://zhuanlan.zhihu.com/p/279287735
微信的GraphTR模型的思路:
GraphTR是为了要学习优质tag embedding,为此要注重利用用户的行为信息。但是由于user-tag的行为太稀疏,因此GraphTR需要通过user-video的行为学习到tag embedding。要达成以上目标,也有多种作法。
GraphTR的做法是:
将user, video, tag(还加上video的来源media)都放入一个大的异构图
通过图卷积,学习到video embedding,再建模video与video之间的相关性(比如在同一个session中播放过
因为video embedding融合了tag embedding,因此在优化目标达成之后,一个优质的副产品就是得到tag embedding。
-
构建图
图上要包括:user, video, tag, media (视频来源)这 4类节点。因为用户数目太多,而每个用户的行为相对稀疏,GraphTR将用户按照gender-age-location分成84000组,用user group替代user,在图中建模。
而图上要包括以下5类边(这一版本暂时不考虑边上的权重):
video-video:同属一个观看session中的两video之间有边
user-video:某视频被某user group一周观看超过3次。 (因为user-tag行为稀疏,因此图中没有user-tag的边)
video-tag:video和其携带的tag
video-media:video和其来源
tag-tag:两个 tag属于同一个视频
-
聚合异构节点
为了完成user, video, tag, media这四类节点的信息融合,GraphTR 设计了3层卷积结构,称为Heterogeneous field interaction network (HFIN)。
-
建模节点相关性
建模video-video之间的相关性,在同一个session被观看的视频之间,距离要尽可能小。因为video的点击行为比较多,这方面的数据比较丰富,文中采用的是这种方案。loss 使用 w2v
-
应用 tag emb
拿用户观看过视频携带的tag的embedding加权平均得到user embedding,再拿这个user embedding在当前视频所携带的tag的embedding中寻找出距离最近的top-k个tag,作为推荐结果显示在视频的下方。因为这些tag embedding蕴含了丰富的user-video行为信息,不仅有助于提升用户对tag的点击率,也有助于提升进入沉浸式tag频道后的观看时长。
总结:
微信团队面临的是,数据少的领域如何借力于数据多的领域,同时要兼顾两个领域的优化目标。而他们没有采取传统的“迁移+多目标”的方式,而是通过将不同领域的不同节点、关系建立在一张异构图上,通过图卷积,使得每个节点的embedding都浓缩了多个领域的知识,达成了“知识迁移+目标兼顾”。GraphTR在微信这种大规模推荐场景下的成功运用,展现了GNN在迁移学习、多任务学习方面的强大能力,为我们解决类似问题提供了全新的思路。
GraphTR 采用了GraphSAGE+FM+Transformer多种手段,粒度上从粗到细,交叉、聚合来自不同领域的异构消息,相比于mean/max pooling、浅层FC等传统聚合方式,极大提升了模型的表达能力,值得借鉴。
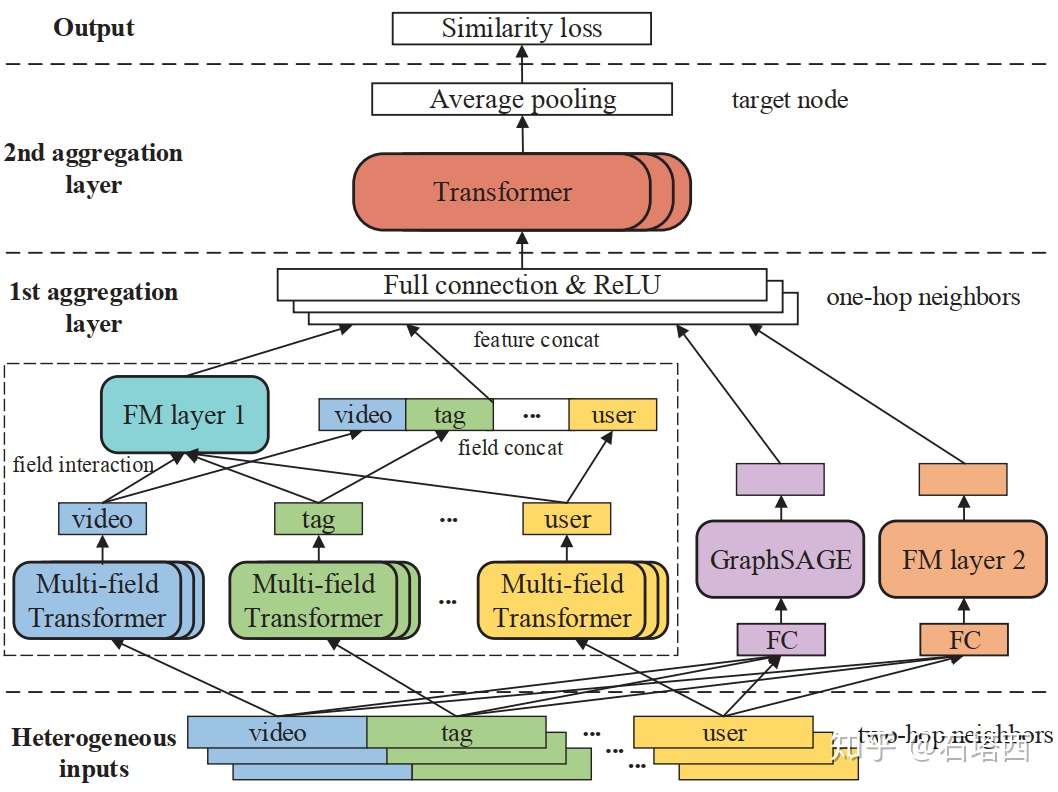
下图结构:
首先定义目标节点,找出一跳二跳的节点。
1 agg layer 输入二跳节点,输出一跳节点的 emb
2 agg layer 输入一跳节点 emb,经 avg pool 输出 target node 的 emb
所有异构节点共享 emb 空间,表征用户偏好,相邻节点空间相近。
loss 衡量临近相似度,好处是最大化利用视频相关行为和profile,学习用户在 video 的偏好,同时学到用户在 tag 偏好。
正例:被相同用户看过的两个视频 / 相同tag的两个视频 / 相同media的两个视频
计算框架
Tencent Angel
https://github.com/Angel-ML/angel 腾讯 PS 计算框架,支持推荐算法和图网络算法:
1 | 图挖掘: PageRank、Kcore、Closeness,共同好友、三角结构、社团发现、其他; |
TI-ML
https://tesla.xx.com/gitbook/doc/graph/tdw-ml-tx_graph-vital_nodes_identification.html 腾讯云算法平台,支持图算法
1 | 社团发现 |
Wechat Plato
https://github.com/Tencent/plato 微信图计算框架,支持算法有:
1 | 图特征 |
https://git.code.xx.com/TencentGraph/PlatoEmbedding
https://tesla.xx.com/react/index.html#/algorithm-market/home
Alibaba Euler
https://github.com/alibaba/euler/ 阿里图计算框架,支持算法:
LsHNE
https://github.com/alibaba/euler/wiki/LsHNE
针对搜索广告召回的大规模异构网络Embedding方法。
解决 NE 在淘宝数据集上的挑战:节点、边类型丰富;向量距离敏感;节点属性未利用的
无监督,样本采样 Node2vec Walk ,目标
LasGNN
https://github.com/alibaba/euler/wiki/LasGNN
ScalableGCN
https://github.com/alibaba/euler/wiki/ScalableGCN
Reference
[0] https://zhuanlan.zhihu.com/p/33732033
[1] DeepWalk: Online Learning of Social Representations
[2] LINE: Large-scale Information Network Embedding
[3] node2vec: Scalable Feature Learning for Networks
[4] Structural Deep Network Embedding
[5] 深度学习中不得不学的Graph Embedding方法 https://zhuanlan.zhihu.com/p/64200072
[7] Item2Vec: Neural Item Embedding for Collaborative Filtering https://arxiv.org/abs/1603.04259
