注意力机制的演化
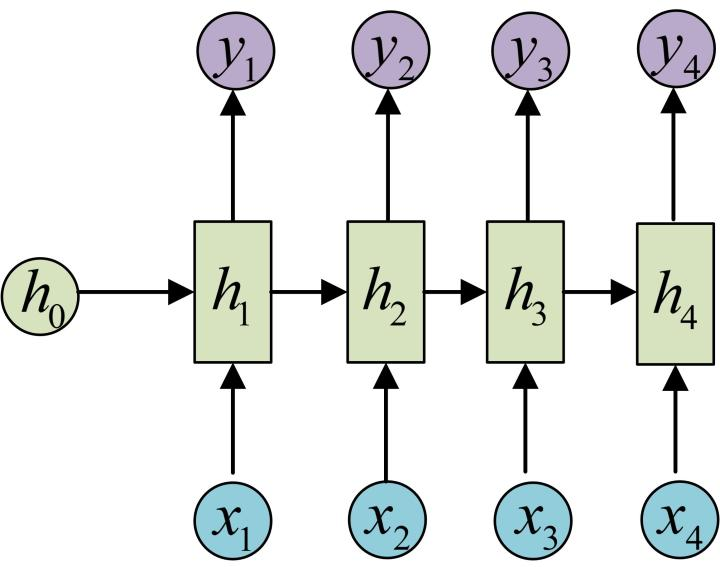
RNN
N vs N
输入输出等长
 $$
h_i = f(ax_i + bh_{i-1} + c)
$$
$$
h_i = f(ax_i + bh_{i-1} + c)
$$
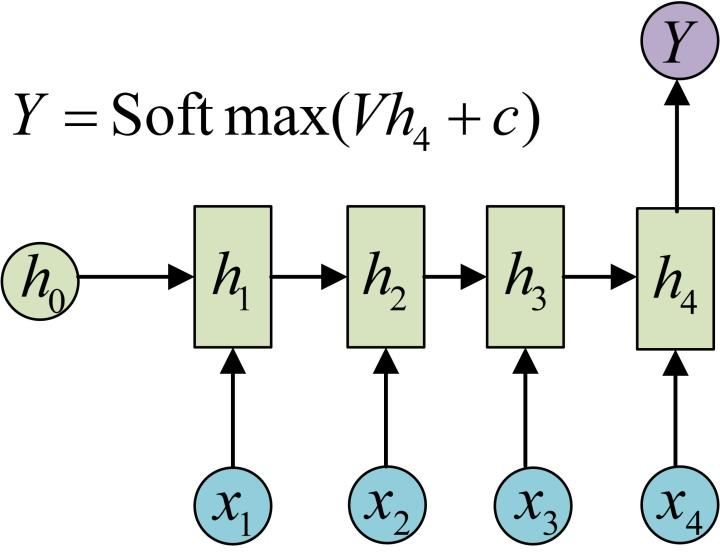
N vs 1
输入 N 输出 1
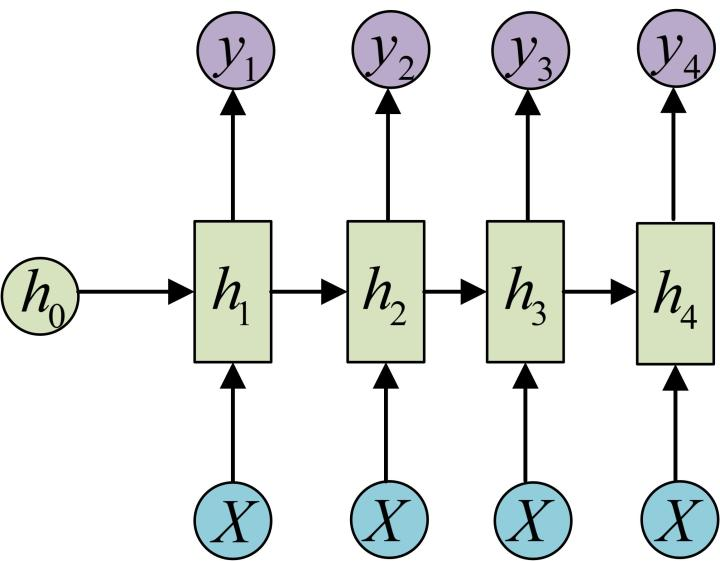
1 vs N
输入 1 输出 N
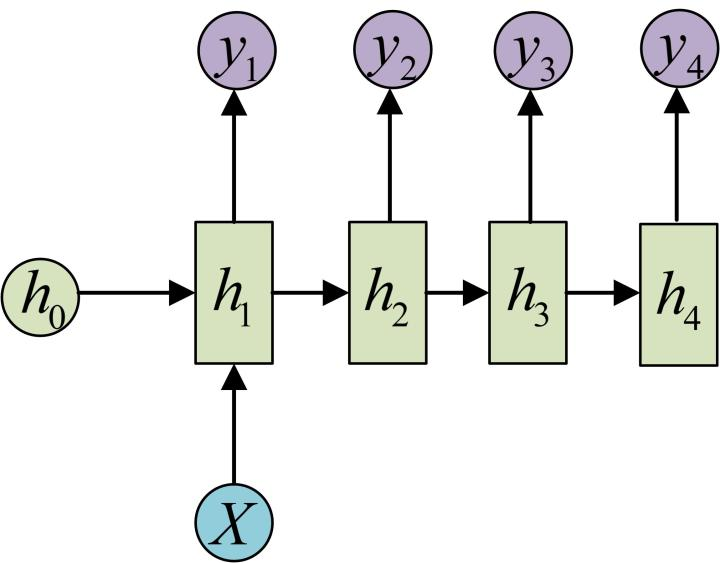
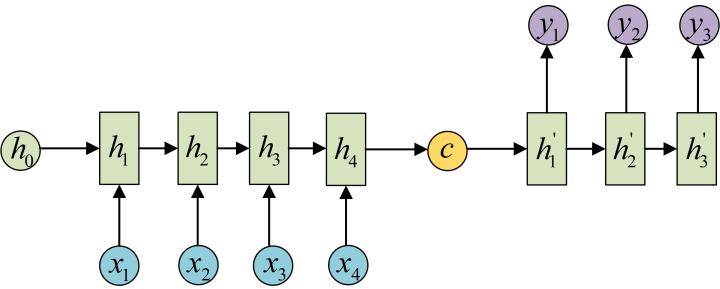
N vs M / Encoder-decoder / Seq2seq(变长)
输入 N 输出 M,如翻译问题,输入输出的单词不等长。
Encoder 将输入编码为 c,再作为输入传入 decoder。
LSTM
LSTM 为了解决 RNN 梯度消失问题,在 RNN 结构的基础上:
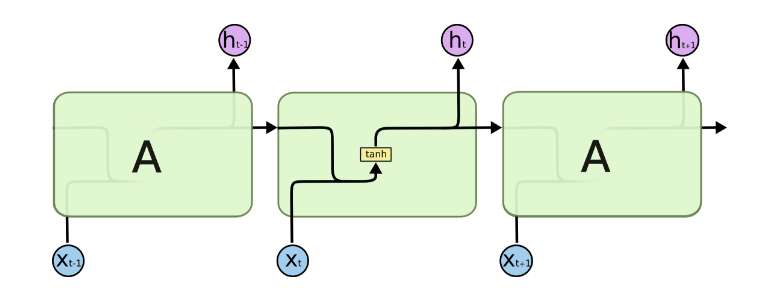
增加了遗忘门,一定概率遗忘上一层隐藏层的状态:

GRU
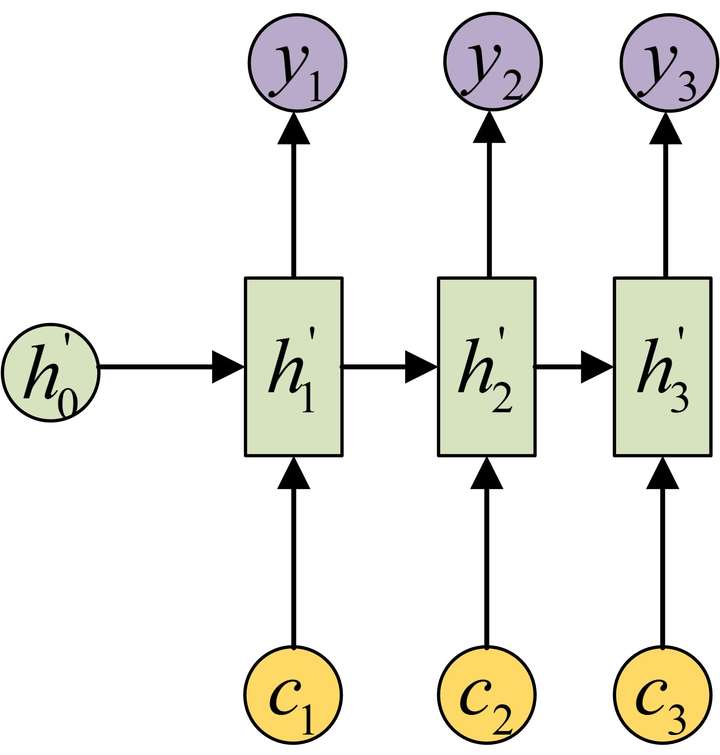
RNN + Attention (Encoder-decoder)
Attention机制通过在每个时间输入不同的c来解决问题
下图是带有 attention 机制的 decoder
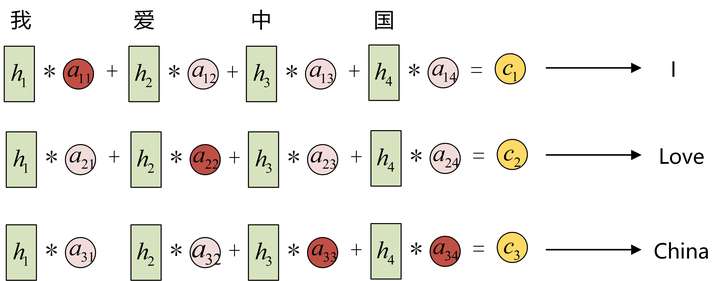
以 encoder-decoder 翻译任务为例,输入的序列是“我爱中国”,因此,Encoder中的 、、、就可以分别看做是“我”、“爱”、“中”、“国”所代表的信息。在翻译成英语时,第一个上下文 应该和“我”这个字最相关,因此对应的 就比较大。 应该和“爱”最相关,因此对应的 就比较大。最后的 和 、 最相关,因此 、 的值就比较大。
Attention QKV
以下是 attention 机制单独使用的例子。
输入 ,Memory 中以 形式存储需要的上下文,其中 是 question, 是 answer, 是新来的 question,根据与 相似的历史 ,带权 求和,输出 。
计算步骤
- 在 Memory 中寻找相似 k(score function):,其中 是打分函数(注意力分布),可选:
- 加性模型
- 点积模型
- 缩放点积模型
- 双线性模型
- 归一化(alignment function):
- 读取内容(context vector function):
数化简成一个公式:(打分函为缩放点积模型)
其中
Self-attention
Q K V 均来自统一输入
Traditional Attention
Attention 总结
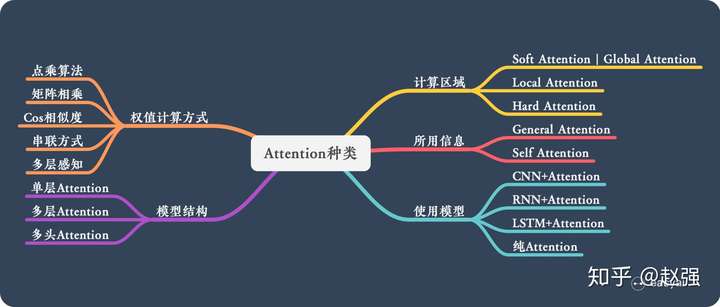
计算区域
Soft attention:对所有key求权重,进行加权
Hard attention:对一个 key 权重为 1,其余权重为 0。无法求导,因此需要用强化学习。
Local attention:用 hard 方法定位到一个区域,区域内用 soft 方法
所用信息
Genreal attention:
Local attention:
Self attention:如 AutoInt
结构层次
单层 attention:常用方法,用一个 query 对一段原文进行一次 attention
多层 attention:一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
多头 attention:《Attention is All You Need》用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention
模型
CNN + attention:
LSTM + attention:
相似度计算
点乘:
矩阵相乘:
cos 相似度:
串联方式:
MLP:
参考
https://zhuanlan.zhihu.com/p/91839581
https://zhuanlan.zhihu.com/p/85038315
蘑菇街推荐算法之迷——Self Attention不如Traditional Attention? https://mp.weixin.qq.com/s/3nTevkiLLaZ6eX7nZWzvTg
