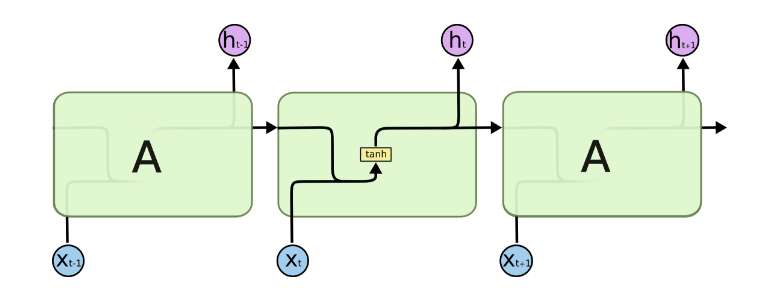
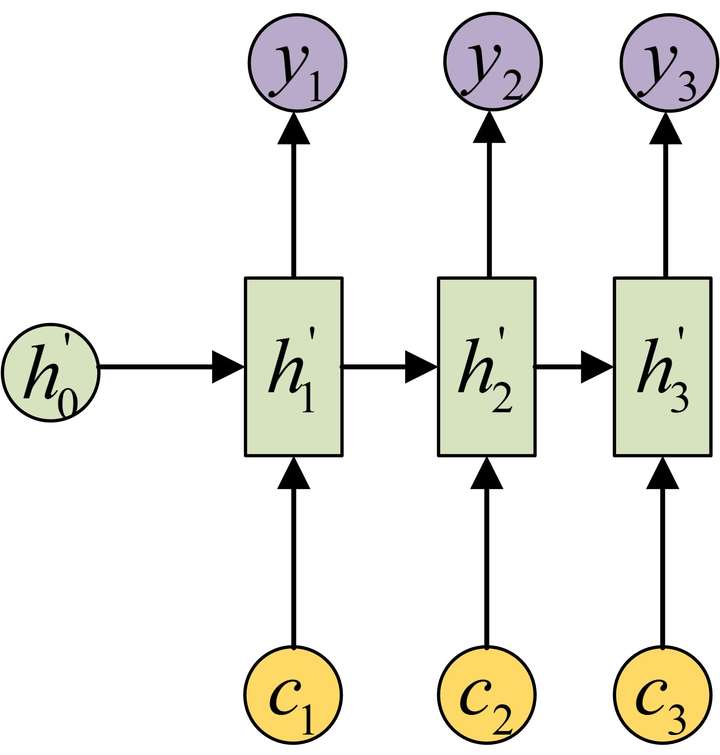
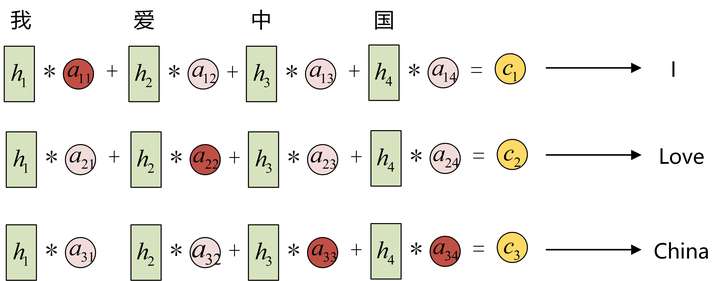
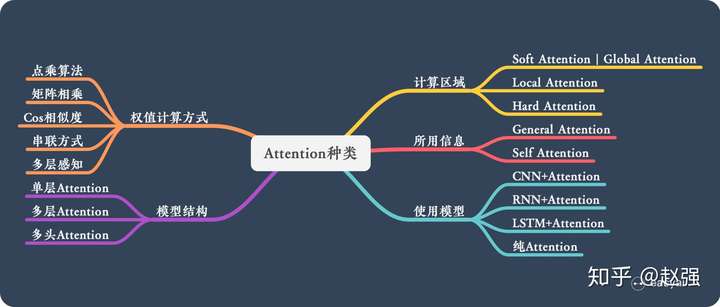
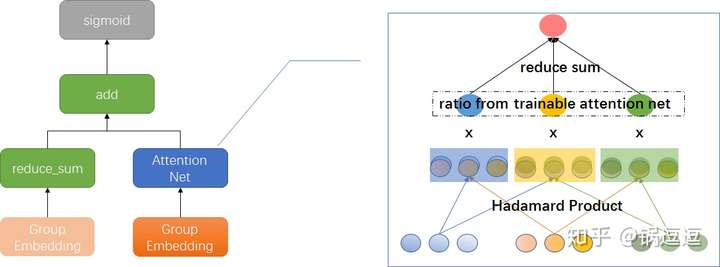
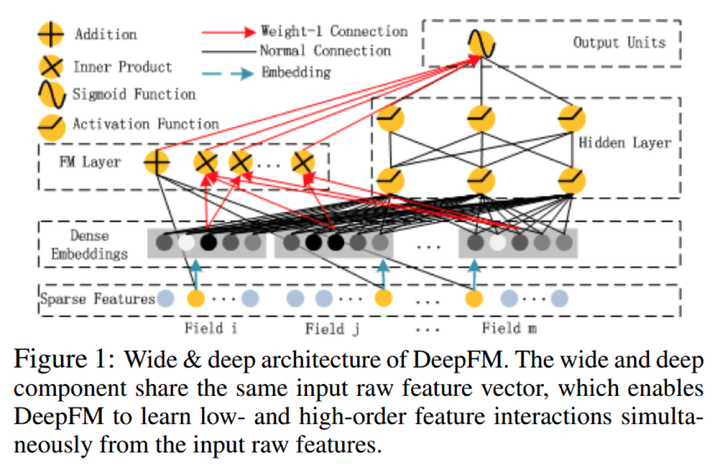
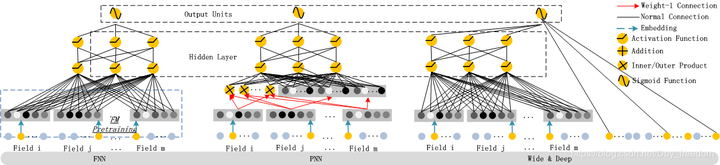
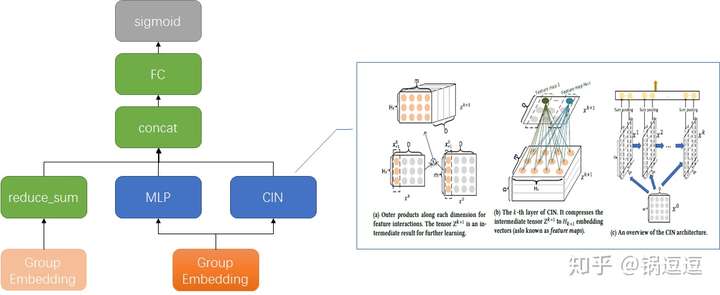
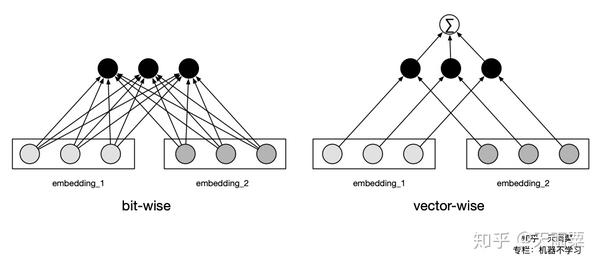
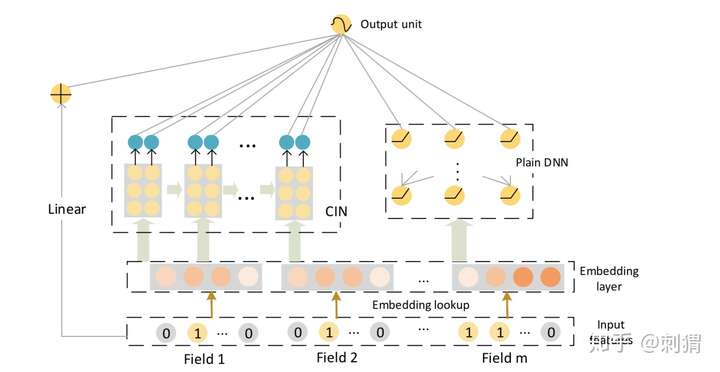
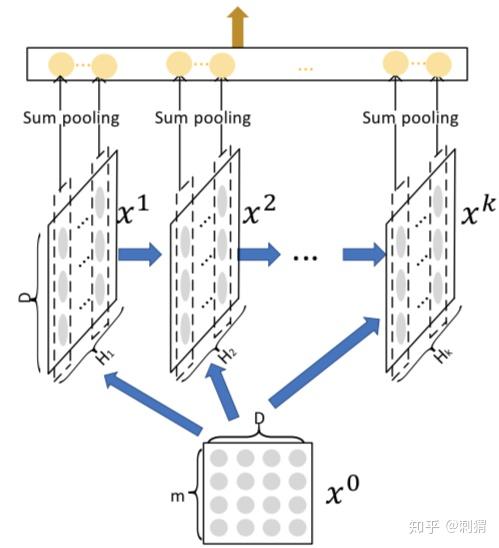
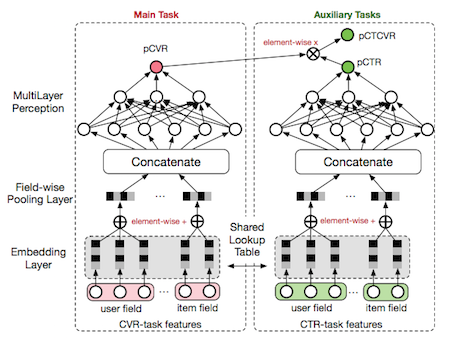
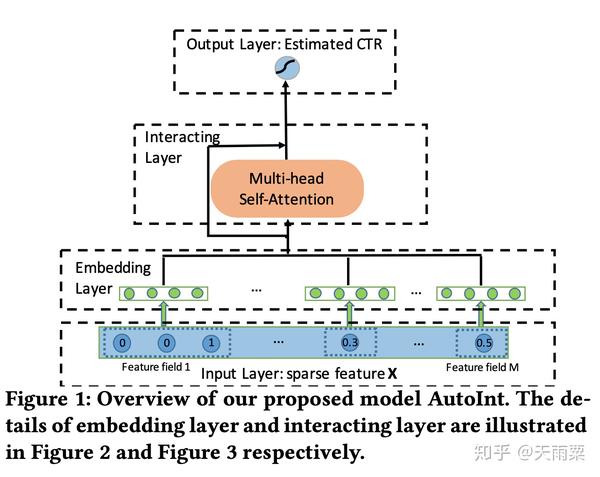
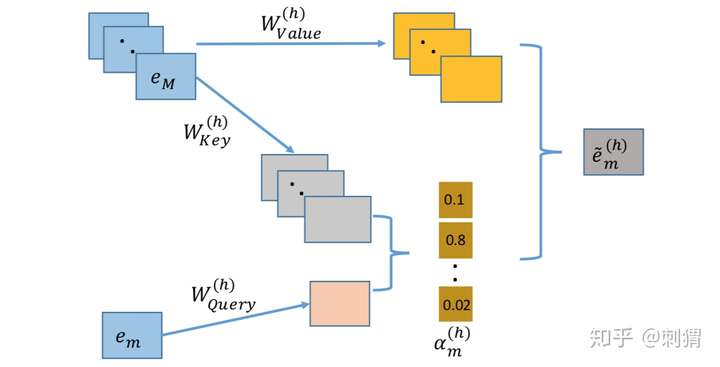
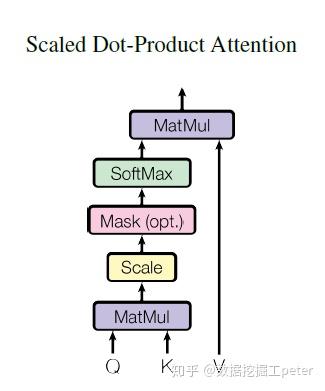
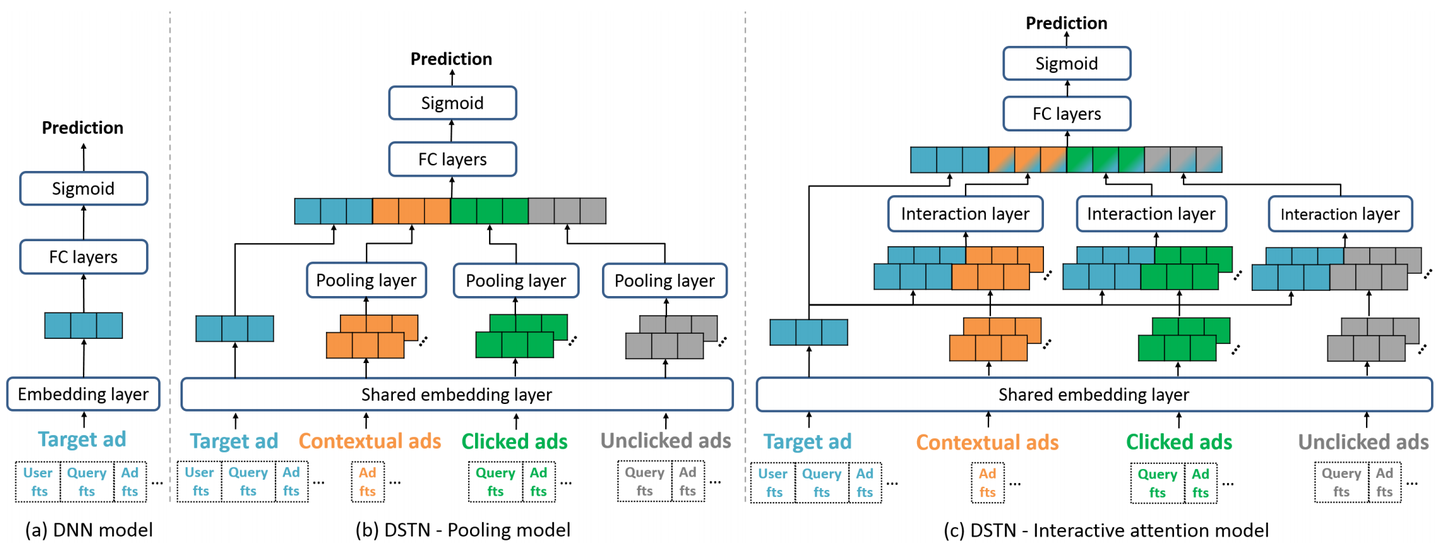
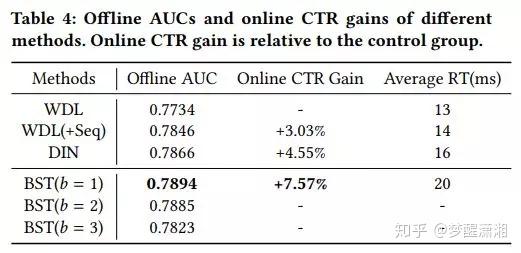
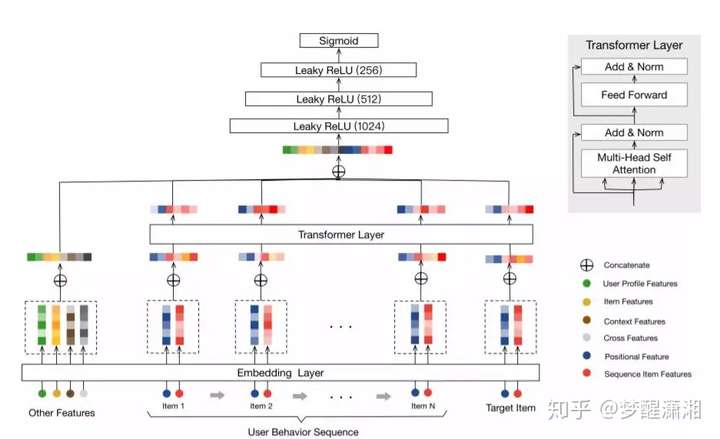
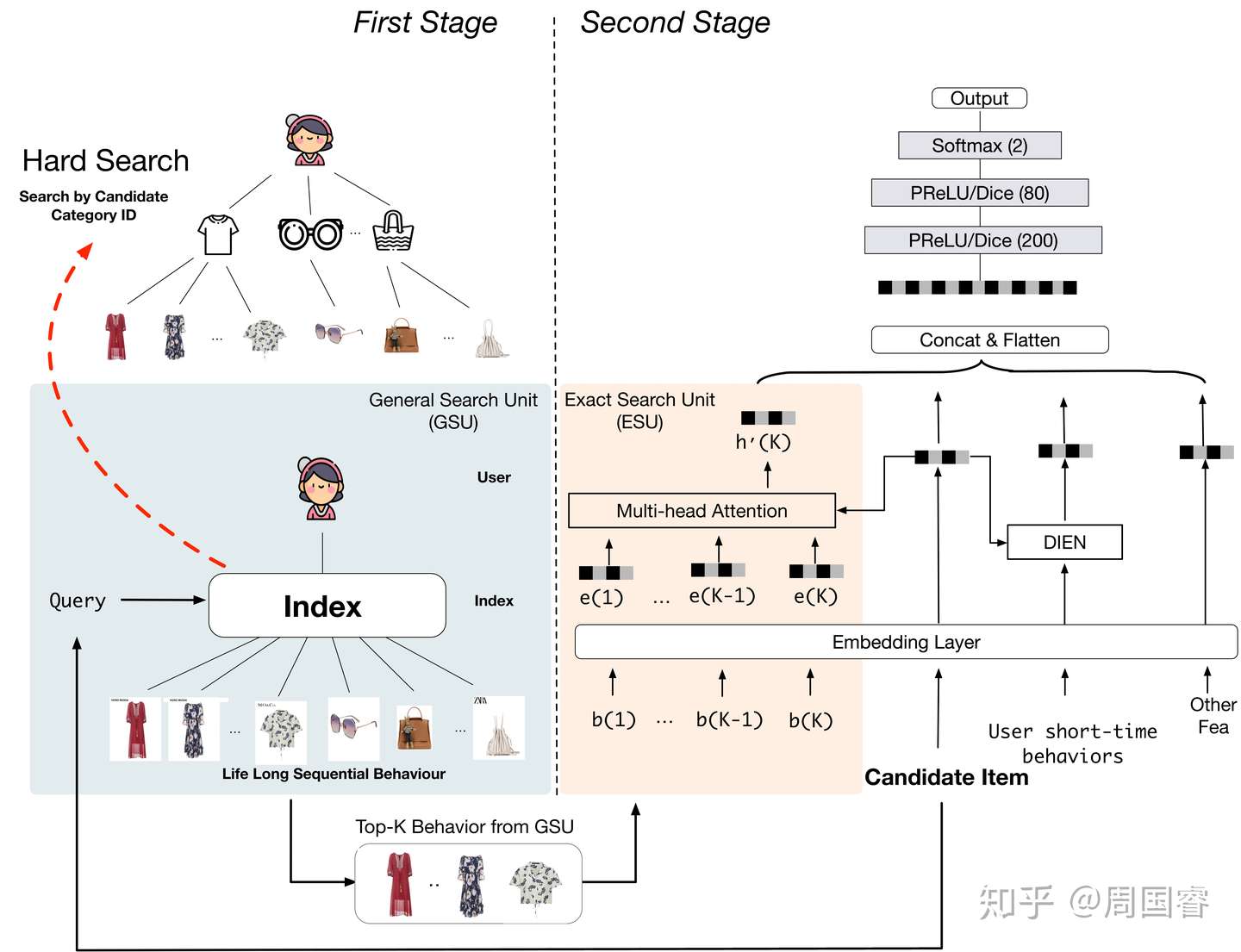
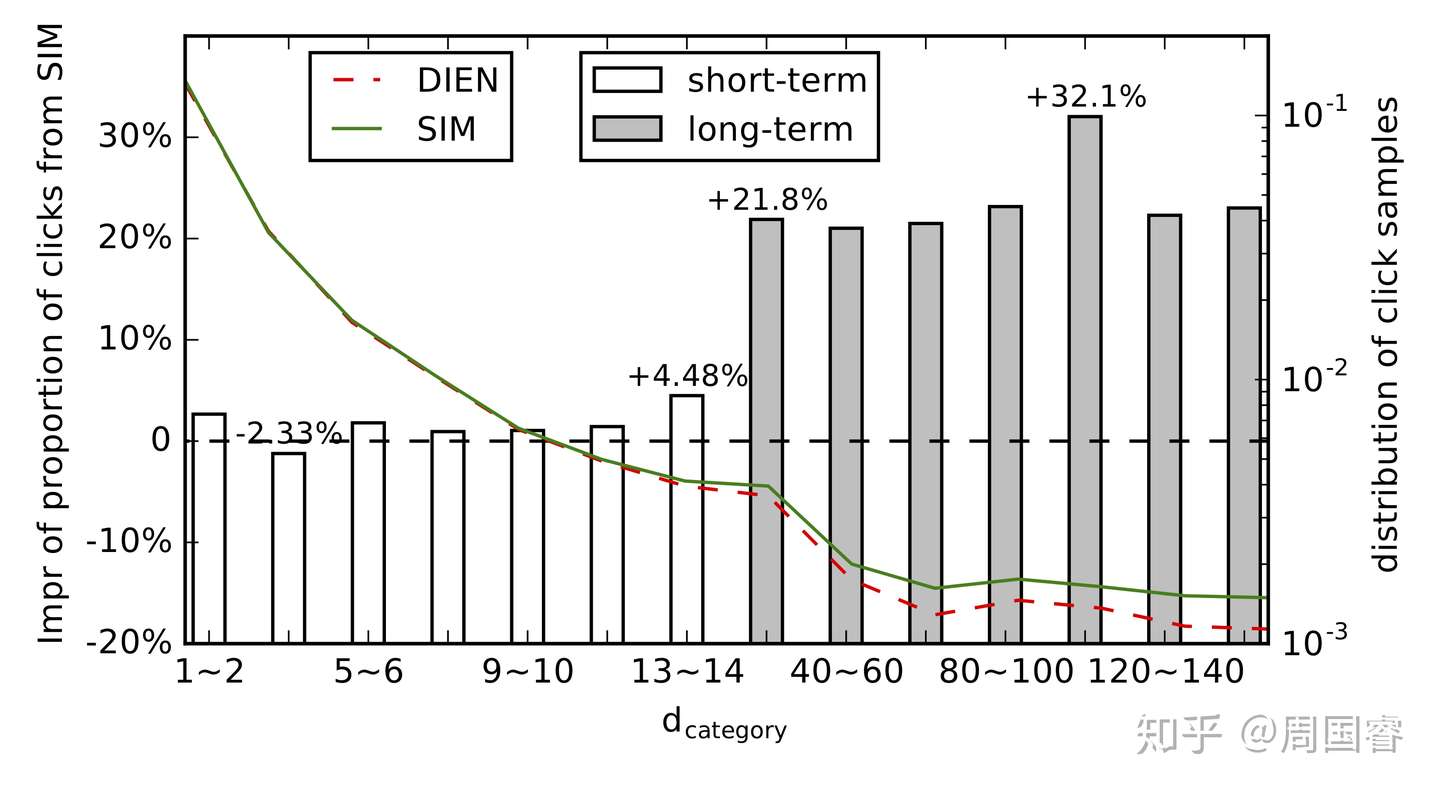
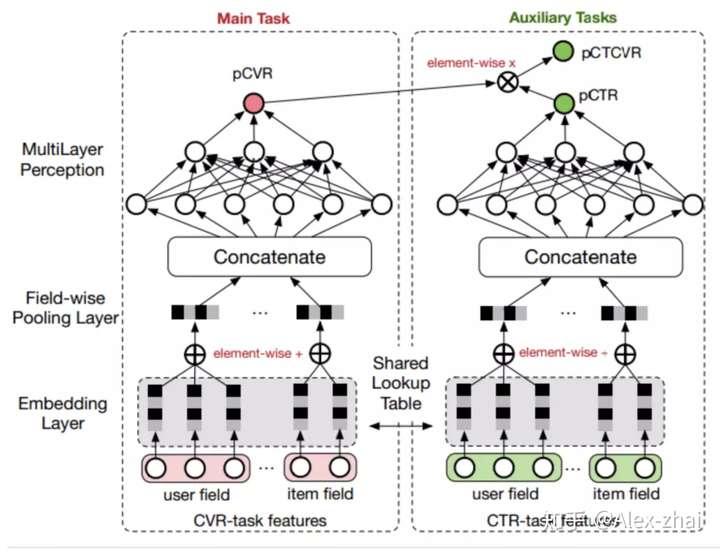
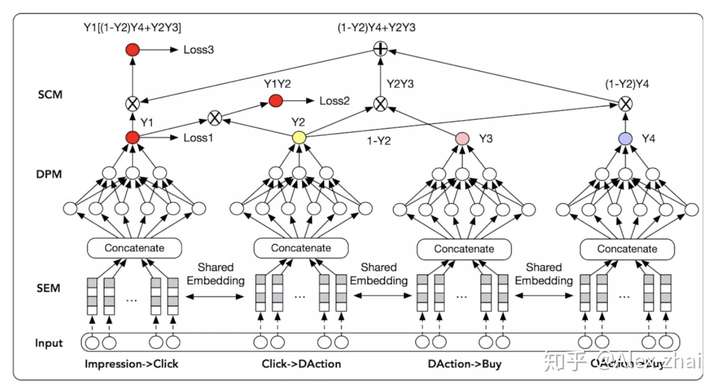
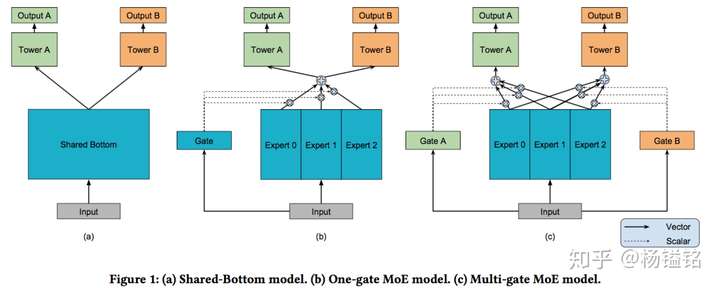
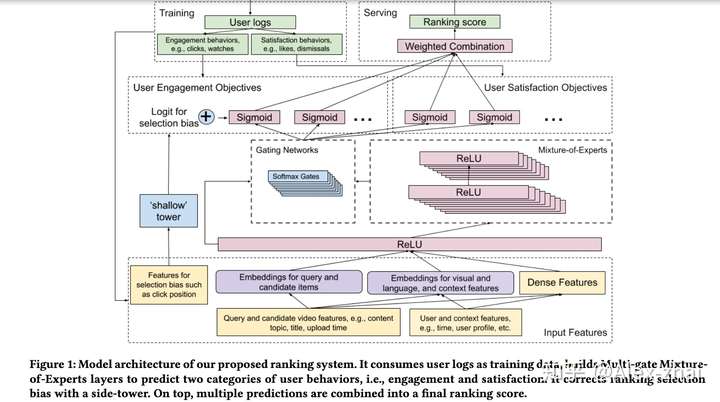
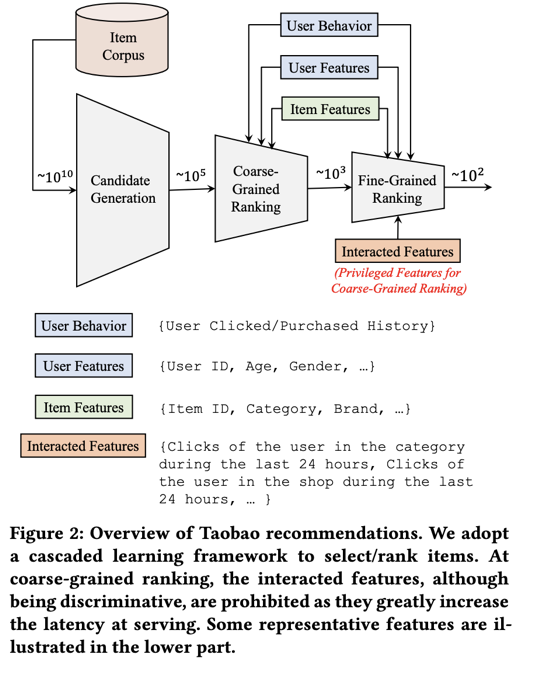
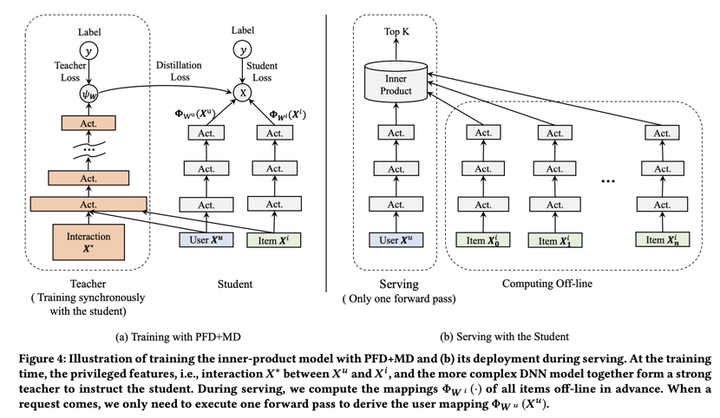
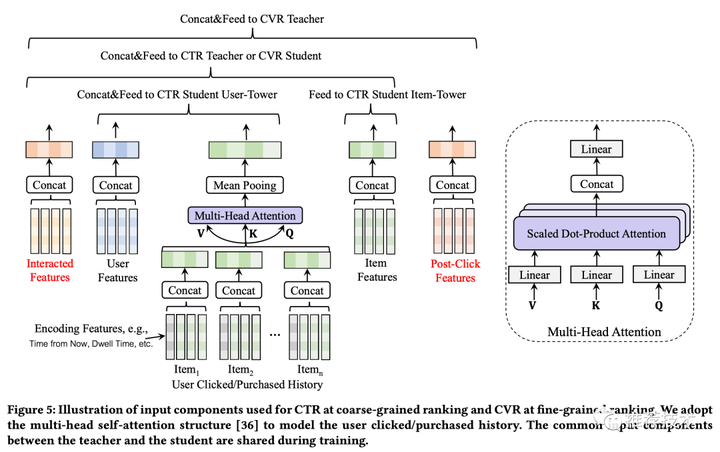
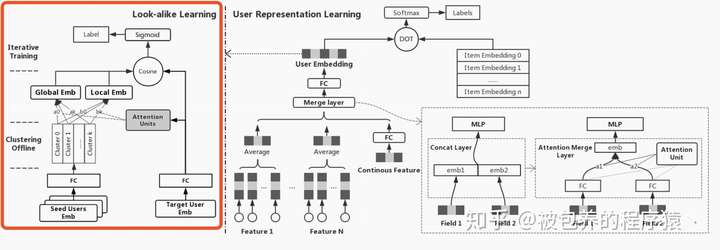
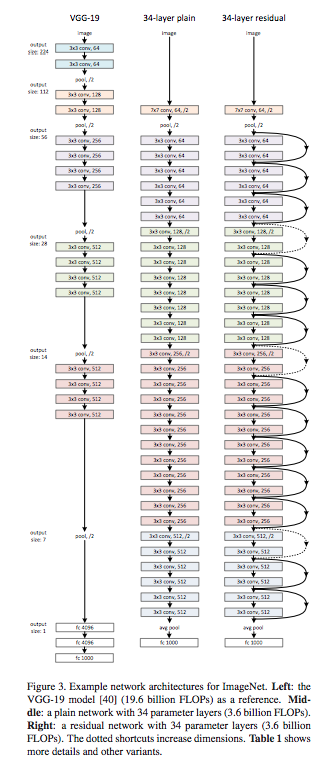
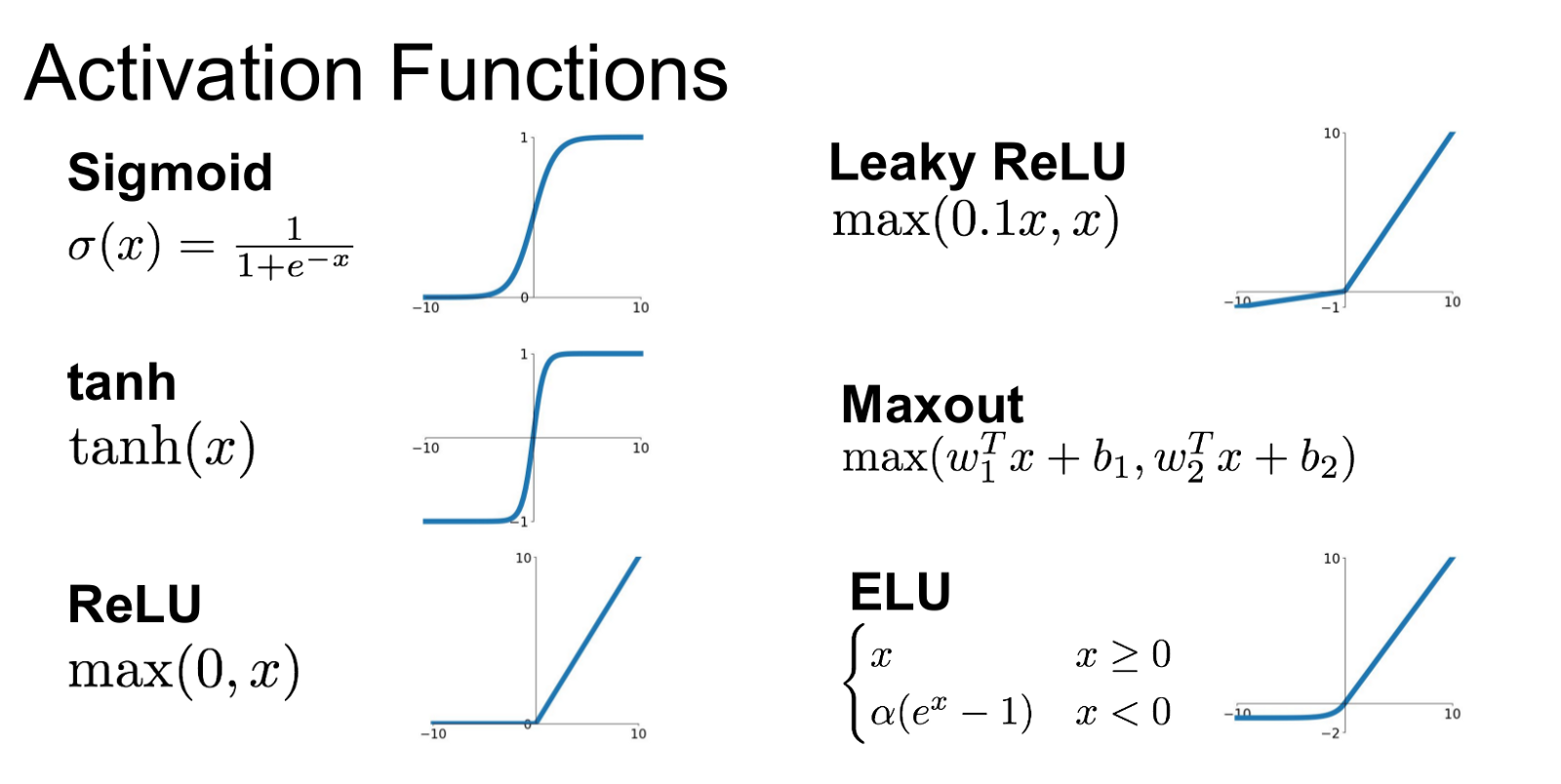
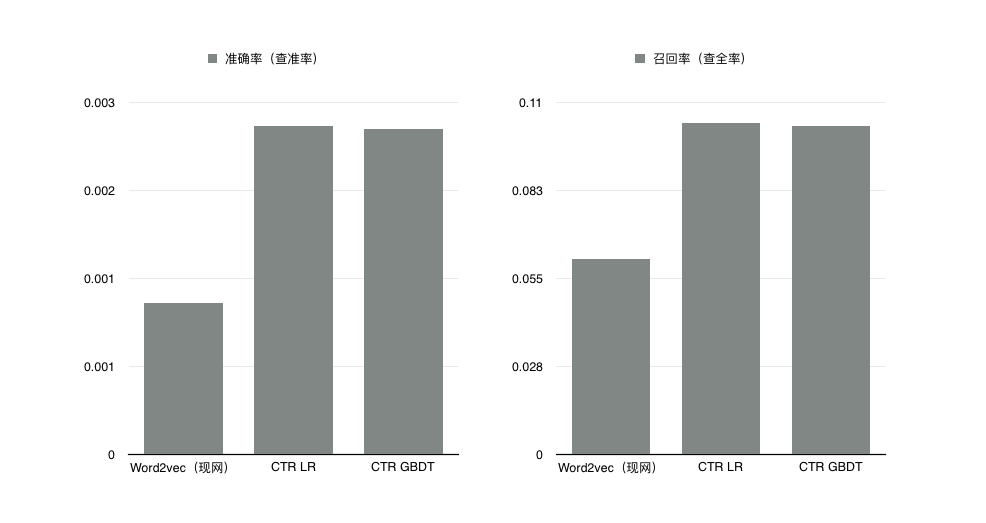
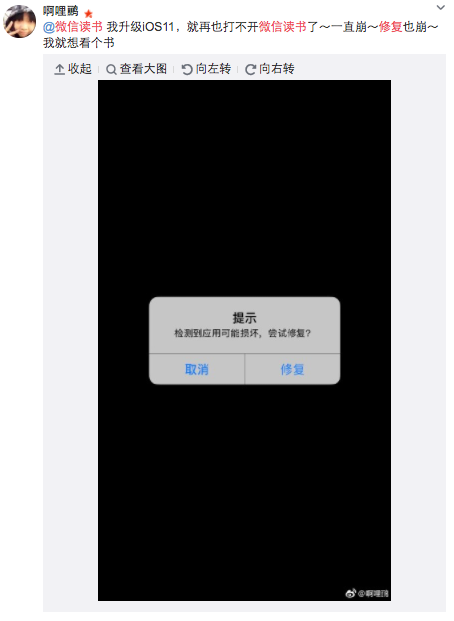
问题
问题:给定用户特征,预估未来n天的付费概率、付费金额
样本:用户特征 ,标签是未来n天是否付费 、付费金额 。
数据分布特点:
- 90% 用户不付费,10% 用户付费
- 付费用户中,90% 是低付费用户,9% 是高付费用户,1% 是超高付费用户
建模
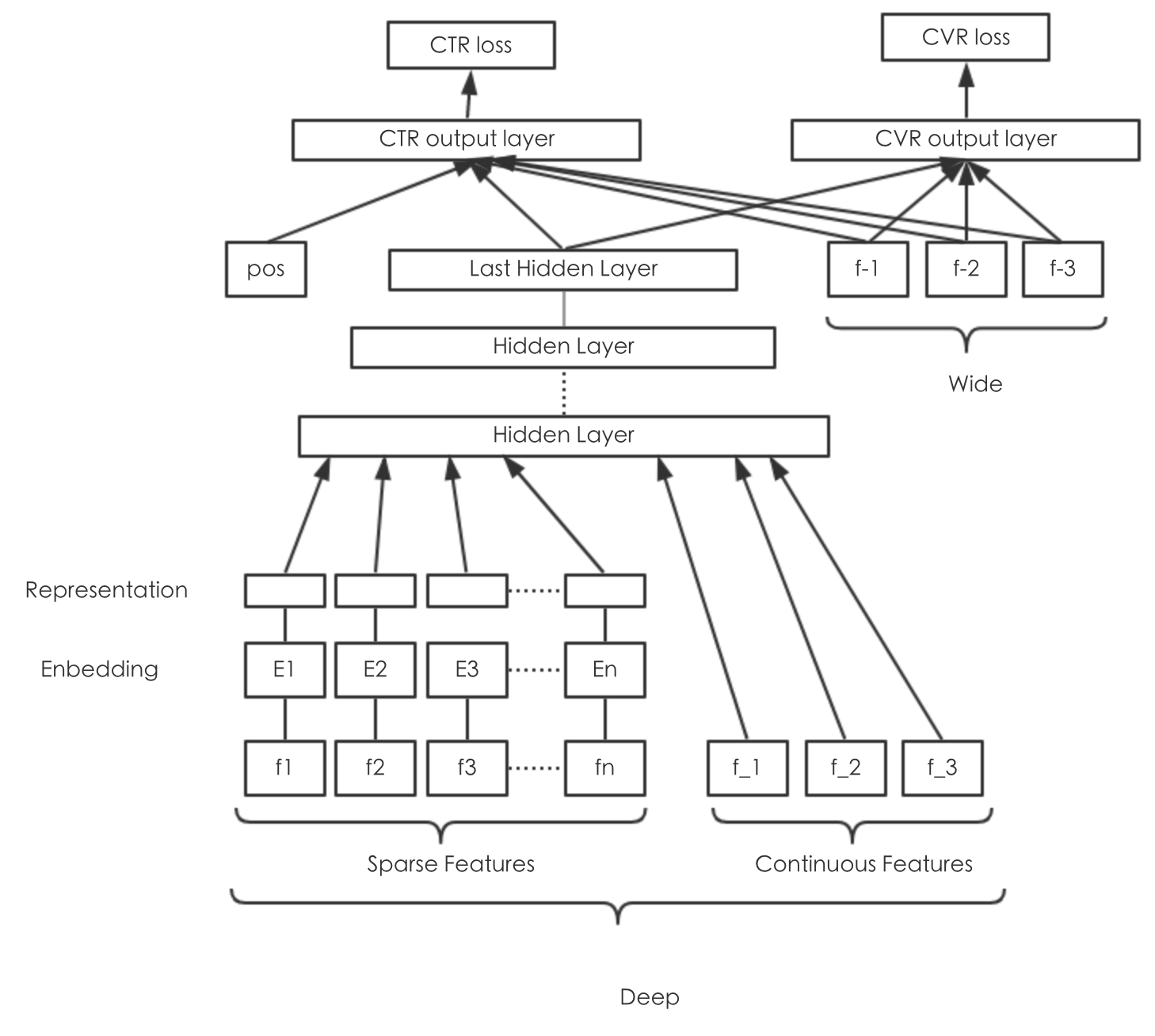
多任务模型,分别预估付费概率和付费金额
付费概率预估损失函数有:
- 交叉熵损失函数
付费金额预估损失函数有:
其中 是用户样本, 是付费金额; 分别是付费概率、付费金额均值、付费金额标准差。
MSE Loss 假设拟合误差服从标准正态分布,Loss 是关于均值对称的,对高付费样本,产生较大的 Loss。
ZILN Loss 假设随机变量 LTV 服从对数正态分布,对高付费样本,不会产生较大的 Loss。

考虑样本 LTV 更接近对数正态分布,本文使用 ZILN Loss 建模,获得效果提升。
推导
模型定义
其中 激活函数分别是 sigmoid identity softplus;pay_amount 等于服从对数正态分布的随机变量期望。
其中 表示付费概率; 表示均值和标准差,是付费金额服从对数正态分布的参数。

损失函数推导
记 为 , 为
求参数 使得极大似然函数最大
其中
评估
绘制洛伦兹曲线如下图,使用基尼系数(= 预测曲线下面积 / GT 曲线下面积)评估回归模型,使用 AUC 评估分类模型。

使用十分位图评估对不同分数层用户的预测效果:

参考
《A-deep-probabilistic-model-for-customer-lifetime-value-prediction》 PDF 2019 DeepAI Google
《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》PDF 2019 阿里
附录
正态分布
概率密度函数 wiki

对数正态分布
概率密度函数 wiki

期望
方差
如果随机变量 的对数服从正态分布,则这个随机变量服从对数正态分布。
如果 是正态分布的随机变量,则 为对数正态分布。
如果 是对数正态分布,则 为正态分布。
如果一个变量可以看作是许多很小独立因子的乘积,则这个变量可以看作是对数正态分布。一个典型的例子是股票投资的长期收益率,它可以看作是每天收益率的乘积。
中心极限定理
大量统计独立的随机变量的平均值的分布趋于正态分布。
LogNormal Loss 推导
假设随机变量 符合 Log Normal 分布,其概率密度函数为
从对数最大似然函数可以推导出 LogNormal Loss
TF 实现,其中 loc scale label 对应 :
1 | regression_loss = -tf.keras.backend.mean(tfd.LogNormal(loc=loc, scale=scale).log_prob(labels),axis=-1) |
MSE Loss 推导
假设目标与输入变量存在如下关系,且误差服从标准正态分布
正态分布概率密度函数
误差概率密度函数
给定 模型输出 的概率 为
从对数最大似然函数可推导出 MSE Loss
MAE Loss 推导
假设目标与输入变量存在如下关系,且误差服从拉普拉斯分布
拉普拉斯概率密度函数
误差概率密度函数
给定 模型输出 的概率 为
从对数最大似然函数可推导出 MSE Loss
Huber Loss
将 MSE 与 MAE 结合起来,[-1,1] 用 MSE 平滑,其余区间用 MAE。
对比
MSE 比 MAE 收敛更快
MAE 比 MSE 对异常点更加鲁棒

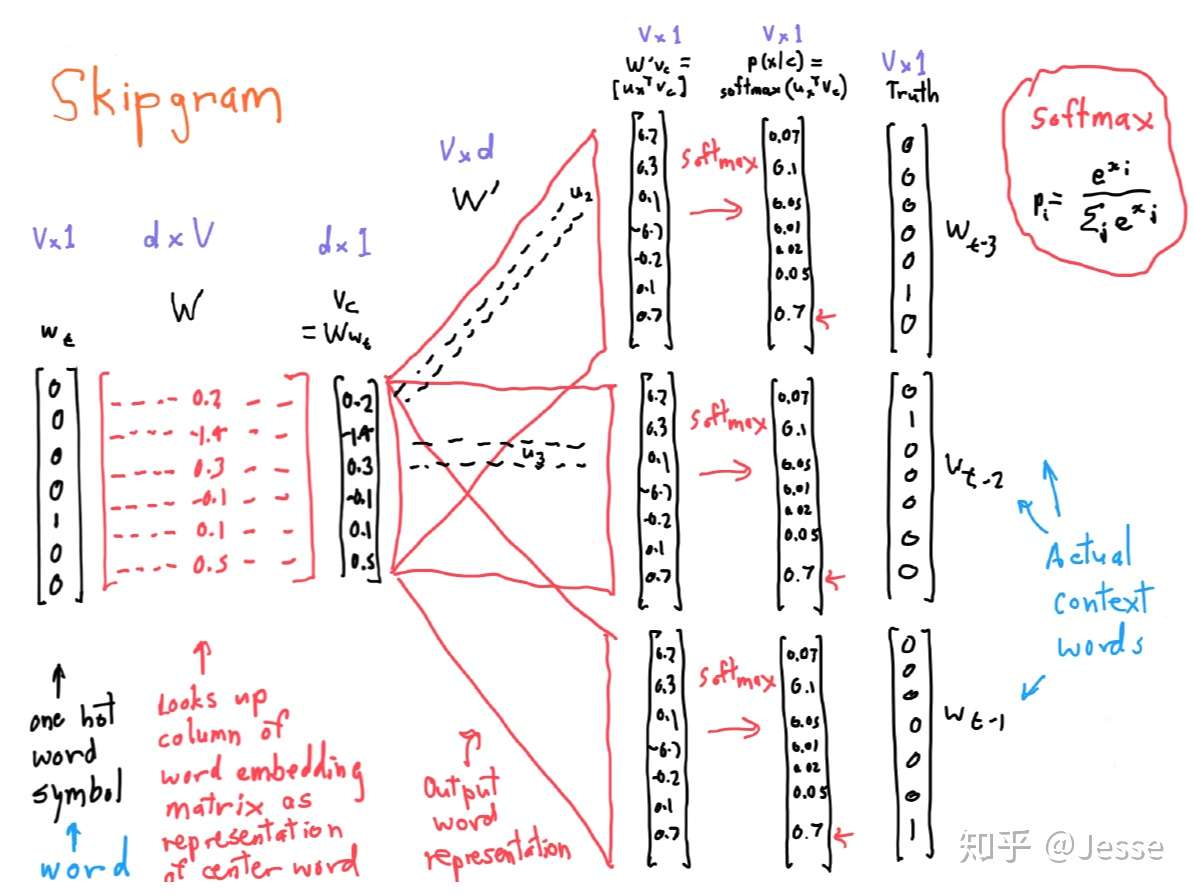
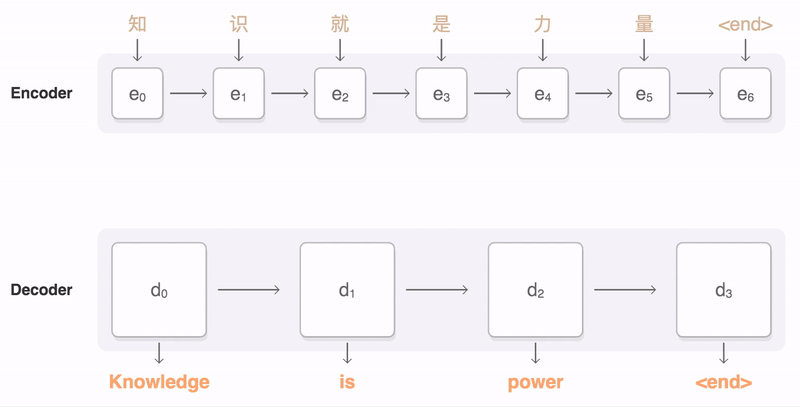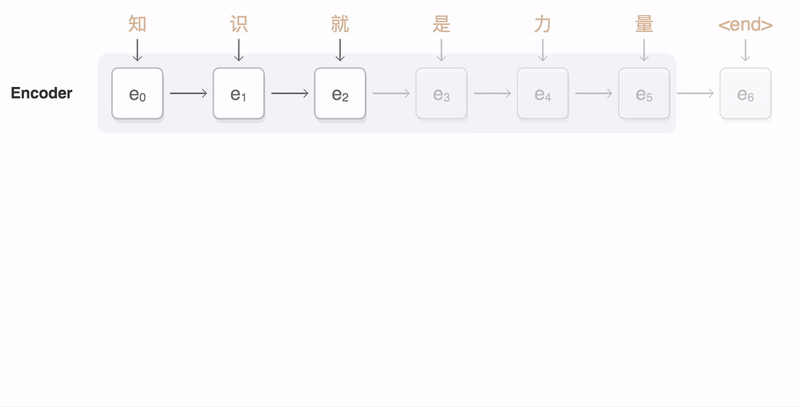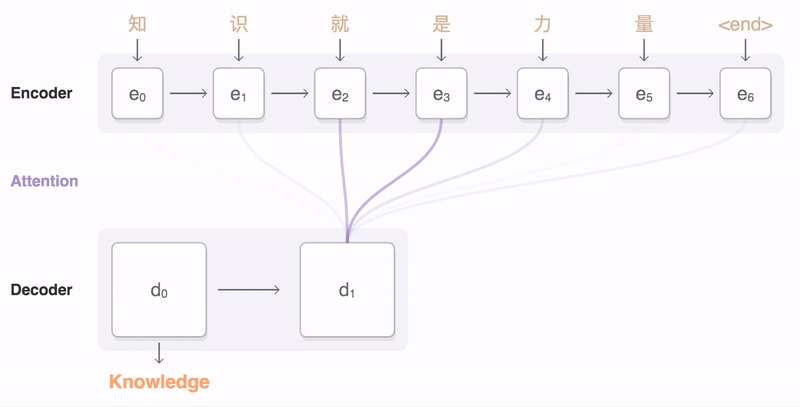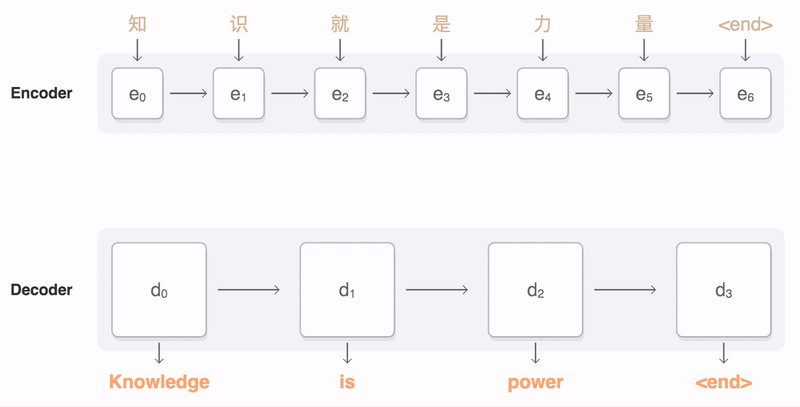


 $$
h_i = f(ax_i + bh_{i-1} + c)
$$
$$
h_i = f(ax_i + bh_{i-1} + c)
$$